In this R tutorial, you will learn how to remove duplicates from the data frame. First, you will learn how to delete duplicated rows and, second, you will remove columns. Specifically, we will look at how to remove duplicate records from the data frame using 1) base R, and 2) dplyr.
Table of Contents
- Outline
- Prerequisites
- Example Data
- Example 1: Remove Duplicates using Base R and the duplicated() Function
- Example 2: Remove Duplicate Columns using Base R’s duplicated()
- Example 3: Removing Duplicates in R with the unique() Function
- Example 4: Delete Duplicates in R using dplyr’s distinct() Function
- Example 5: Delete Duplicate Rows Based on Columns with the distinct() Function
- Conclusion
- Other Useful R Tutorials
Outline
The post starts by answering a few questions (e.g., “How do I remove duplicate rows in R?”). In the second section, you will learn what is required to follow this R tutorial. That is, you will learn about the dplyr (and Tidyverse) package and how to install them. When you have what you need to follow this R tutorial, we will create a data frame containing duplicated rows and columns that we can practice. In the next 5 sections, we will have a look at the example of how to delete duplicates in R. First, we will use Base R and the duplicated() and unique() functions. Second, we will use the distinct() function from dplyr.

To delete duplicate rows in R you can the duplicated() function. Here’s how to remove all the duplicates in the data frame called “study_df”, study_df.un <- study_df[!duplicated(df)].
Now, that we know how to extract unique elements from the data frame (i.e., drop duplicate items) we are going to learn, briefly, about what is needed to follow this post.
Prerequisites
Apart from having R installed you also need to have the dplyr package installed (this package can be used to rename factor levels in R, and to rename columns in R, as well). You need dplyr if you want to use the distinct() function to remove duplicate data from your data frame. R packages are, of course, easy to install. You can install dplyr using the install.packages() function. Here’s how to install packages in R:
# Installing packages in R:
install.packages("dplyr")Code language: R (r)It is worth noting here that dplyr is part of the Tidyverse package. This package is super helpful because it comes with other excellent packages such as ggplot2 (see how to create a scatter plot in R with ggplot2, for example), readr, and tibble. To name a few! That said. Let’s create some example data to practice dropping duplicate records from!
Example Data
Now, to practice removing duplicate rows and columns, we need some data. Here’s some data with two duplicated rows and two duplicated columns:
# Creating a data frame:
example_df <- data.frame(FName = c('Steve', 'Steve', 'Erica',
'John', 'Brody', 'Lisa', 'Lisa', 'Jens'),
LName = c('Johnson', 'Johnson', 'Ericson',
'Peterson', 'Stephenson', 'Bond', 'Bond',
'Gustafsson'),
Age = c(34, 34, 40,
44, 44, 51, 51, 50),
Gender = c('M', 'M', 'F', 'M',
'M', 'F', 'F', 'M'),
Gender = c('M', 'M', 'F', 'M',
'M', 'F', 'F', 'M'))Code language: R (r)Note, it is also possible to convert a list to dataframe in R. That said, the data frame has 8 rows and 5 columns (we can use the dim() function to see this). Here’s the data frame with the duplicate rows and columns:
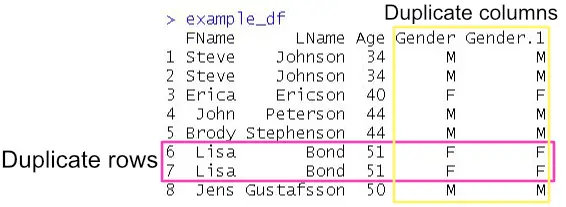
Most of the time, we import our data from an external source. See the following posts for more information:
- Learn How to Convert Matrix to dataframe in R with base functions & tibble
- R Excel Tutorial: How to Read and Write xlsx files in R
- How to Read & Write SPSS Files in R Statistical Environment
- Reading SAS Files in R with Haven & sas7dbat
- How to Read and Write Stata (.dta) Files in R with Haven
In the next section, we are going to start by removing the duplicate rows using base R.
Example 1: Remove Duplicates using Base R and the duplicated() Function
Here’s how to remove duplicate rows in R using the duplicated() function:
# Remove duplicates from data frame:
example_df[!duplicated(example_df), ]Code language: R (r)As you can see, in the output above, we have now removed one of the two duplicated rows from the data frame. What we did, was to create a boolean vector with the rows that are duplicated in our data frame. Furthermore, we selected the columns using this boolean vector. Notice also how we used the ! operator to select the rows that were not duplicated. Finally, we also used the “,” so that we select any columns.
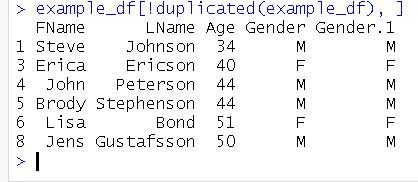
In the image above, we can see that two columns have been removed. Of course, if you want the changes to be permanent, you need to use <-:
# Delete duplicate rows
example_df.un <- example_df[!duplicated(example_df), ]Code language: R (r)Note there are other good operations, such as the %in% operator in R, that can be used, e.g., value matching. If you need to drop rows, see the post about how to remove a row in R.
In the next example, we are going to use the duplicated() function to remove one of the two identical columns (i.e., “Gender” and “Gender.1”).
Example 2: Remove Duplicate Columns using Base R’s duplicated()
To remove duplicate columns we can, again, use the duplicated() function:
# Drop Duplicated Columns:
ex_df.un <- example_df[!duplicated(as.list(example_df))]
# Dimenesions
dim(ex_df.un)
# 8 Rows and 4 Columns
# First five rows:
head(ex_df.un)Code language: R (r)Now, to remove duplicate columns, we added the as.list() function and removed the “,”. That is, we changed the syntax from Example 1 something. Again, we can use the dim() function to see that we have dropped one column from the data frame. Here’s the result from the head() function:

Note, dplyr can be used to remove columns from the data frame as well. In the next example, we are going to use another base R function to delete duplicate data from the dataframe: the unique() function.
Example 3: Removing Duplicates in R with the unique() Function
Here’s how you can remove duplicate rows using the unique() function:
# Deleting duplicates:
examp_df <- unique(example_df)
# Dimension of the data frame:
dim(examp_df)
# Output: 6 5Code language: R (r)As you can see, using the unique() function to remove the identical rows in the data frame is quite straightforward. It is worth noting here, that if you want to keep the last occurrences of the duplicate rows, you can use the fromLast argument and set it to TRUE. If you’re done with data manipulation, you can create a dummy variable in R, for example. See this post for more about the unique function.
In the final two examples, we will use the distinct() function from the dplyr package to remove duplicate rows.
Example 4: Delete Duplicates in R using dplyr’s distinct() Function
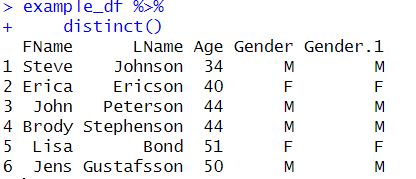
Here’s how to drop duplicates in R with the distinct() function:
# Deleting duplicates with dplyr
ex_df.un <- example_df %>%
distinct()Code language: R (r)In the code example above, we used the function distinct() to keep only unique/distinct rows from the data frame. When working with the distinct() function, if there are duplicate rows, only the first row, of the identical ones, is preserved. Note, if you want to, you can now add an empty column to your data frame. You can do this with tibble, a package that is part of the Tidyverse. In the final example, we are going to look at an example in which we drop rows based on one column.
Example 5: Delete Duplicate Rows Based on Columns with the distinct() Function
It is also possible to delete duplicate rows based on values in a certain column. Here’s how to remove duplicate rows based on one column:
# remove duplicate rows with dplyr
example_df %>%
# Base the removal on the "Age" column
distinct(Age, .keep_all = TRUE)Code language: PHP (php)In the example above, we used the column as the first argument. Second, we used the .keep_all argument to keep all the columns in the data frame. If we use the dim() function again, we can see that we have 5 rows and 5 columns. Let’s print the data frame to see which rows we dropped.
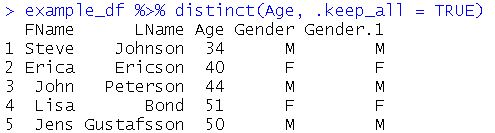
Although we do not want to remove rows where there are duplicate values in a column containing values such as the age of the participants of a study there might be times when we want to remove duplicates in R based on a single column. Furthermore, we can add columns, as well, and drop whether there are identical values across more than one column. Now that you have removed duplicate rows and columns from your dataframe, you might want to use R to add a column to the data frame based on other columns. In a more recent post, you can learn how to use R to remove certain values with dplyr.
Conclusion
In this short R tutorial, you have learned how to remove duplicates in R. Specifically, you have learned how to carry out this task by using two base functions (i.e., duplicated() and unique()) as well as the distinct() function from dplyr. Furthermore, you have learned how to drop rows and columns that are occurring as identical copies in, at least, two cases in your data frame.
Other Useful R Tutorials
Here are some other tutorials you may find useful:
- How to Transpose a Dataframe or Matrix in R with the t() Function
- Learn How to Convert Matrix to dataframe in R with base functions & tibble
- How to use the Repeat and Replicate functions in R
- Select Columns in R by Name, Index, Letters, & Certain Words with dplyr
- How to Generate a Sequence of Numbers in R with :, seq() and rep()
- Cross-Tabulation in R: Creating & Interpreting Contingency Tables
- Modulo in R: Practical Example using the %% Operator
