Are you an R user looking to learn how to use %in% in your data analysis and manipulation tasks? This tutorial is for you and will cover the ins and outs of R’s %in% operator. We will start with the basics, including what %in% means in R and how it differs from the == operator. Then, we will look at some practical applications of %in%, including eight different methods to use this operator in your R scripts. For instance, we will cover how to use %in% to compare sequences of numbers and vectors containing letters or factors and test whether a value is in a column. Additionally, you will discover how to add a new column to a dataframe, subset data, remove columns, and select columns using the %in% operator. And if that is not enough, we will learn how to create a “not in” operator in R. By the end of this post, you will know how to use the %in% operator in your R scripts.
Table of Contents
- Outline
- 8 Ways to Use the %in% Operator in R
- 1: Using %in% to Compare two Sequences of Numbers (vectors)
- 2: Utilizing %in% in R to Compare two Vectors Containing Letters or Factors
- 3: How to use the %in% Operator in R to Test if Value is in Column
- 4: Using %in% in R to Add a New Column to a Dataframe
- 5: Utilizing the %in% in R to Subset Data
- 6: Add a Column using %in% in R
- 7: Using %in% in R to Remove Columns from Dataframe
- 8: Make use of the %in% Operator to Select Columns
- Bonus: Creating a not in operator in R
- Conclusion: R in operator
- R Tutorials
Outline
First, we start with simple examples of using the %in% operator. Specifically, we will look at how to use the operator when testing whether two vectors contain sequences of numbers and letters. As you may already have expected, the operator can be used in other, maybe more advanced cases. The following sections will examine how to work with this operator and dataframes. For example, you will see that you can use the operator to create new variables, remove columns, and select columns.

The %in% operator in R can be used to identify if an element (e.g., a number) belongs to a vector or dataframe. For example, it can be used to see if the number 1 is in the sequence of numbers 1 to 10.
The %in% operator is used for matching values. “returns a vector of the positions of (first) matches of its first argument in its second”. On the other hand, the == operator is a logical operator used to compare if two elements are equal. Using the %in% operator, you can compare vectors of different lengths to see if elements of one vector match at least one element in another. The output length will equal the length of the compared vector (the first one). This is not possible when utilizing the == operator.
The %in% operator matches values in, e.g., two different vectors, as already answered in the two previous questions. You can also use the operator to select certain columns in the dataframe or to subset the dataframe.
If you need to know what is $ in r, another operator, check the linked post. Now that you know that %in% is in R, and what is the difference between this operator and == is we can go on and have a look at the example usages.
8 Ways to Use the %in% Operator in R
In this section, we are going through eight examples of using %in% in R. As you already know, we will start by working with vectors. Next, we will explore how to use the operator with dataframes.
1: Using %in% to Compare two Sequences of Numbers (vectors)
In this example, we will use %in% to check if two vectors contain overlapping numbers. Specifically, we will examine how to obtain a logical value for more specific elements, considering whether they are also present in a longer vector. Here is the first example of an excellent usage of the operator:
# sequence of numbers 1:
a <- seq(1, 5)
# sequence of numbers 2:
b <- seq(3, 12)
# using the %in% operator to check matching values in the vectors
a %in% bCode language: R (r)In the code chunk above, we created two numeric vectors, a and b, containing sequences of numbers. The seq() function generates a sequence of numbers in R from the starting value to the ending value in increments of 1 by default.
Importantly, the R %in% operator is then used to check for matching values between a and b. Specifically, a %in% b will return a logical vector indicating which elements in the vector a are also present in the vector b. The output shows us which elements that are the in the shorter vector:

In a real-world example, our vectors might not contain sequences but just random numbers. If we, on the other hand, want to test which elements of a longer vector are in a short vector, we do as follows:
# shorter vector:
a <- seq(12, 19)
# longer vector:
b <- seq(1, 16)
# test if elements in longer vector is in shorter:
b %in aCode language: R (r)
As you can see, both of the above methods will result in a Boolean. Additionally, if we use the which() function, we can use the indexes of where the overlapping elements:
# Using the operator together with the which() function
which(seq(1, 10) %in% seq(4, 12))Code language: PHP (php)Might also interest you: How to use $ (dollar sign) in R: 6 Examples – list & dataframe
In the following example, we will see that we can apply the same methods for letters or factors in R. That is, we will test if two vectors containing letters are overlapping.

2: Utilizing %in% in R to Compare two Vectors Containing Letters or Factors
In this example, we will use %in% to check if two vectors contain overlapping letters. Note, this can also be done for words (e.g., factors). First, we will compare letters in shorter and longer vectors. Here is how to compare two vectors containing letters:
# Sequences of Letters:
a <- LETTERS[1:10]
# Second seq of ltters
b <- LETTERS[4:10]
# longer in shorter
a %in% bCode language: PHP (php)As you can see, and probably already figured out, we used the %in% operator exactly in the same way as for vectors containing sequences of numbers. Again we can test which letters in a long vector are in a short vector:
b %in% aNaturally, as with the examples where we used sequences of numbers in R, the result is a Boolean vector when working with letters, words, or factors. Furthermore, as in the first example, we can use the which() function to get indexes:
g <- c("C", "D", "E")
h <- c("A", "E", "B", "C", "D", "E", "A", "B", "C", "D", "E")
which(h %in% g)Code language: JavaScript (javascript)
Finally, here is an example of why using the %in% operator is better than the ==. If we use which(), together with ==, we will get only the two-three elements:
# %in% vs == the equal operator wrong!
which(g == h)Code language: R (r)In the following example, we will work with a dataframe, instead of vectors. First, however, we are going to read the readxl package to read a .xlsx file in R. Here is how we get our dataframe to play around with:
library(readxl)
library(httr)
#URL to Excel File:
xlsx_URL <- 'https://mathcs.org/statistics/datasets/titanic.xlsx'
# Get the .xlsx file as an temporary file
GET(xlsx_URL, write_disk(tf <- tempfile(fileext = ".xlsx")))
# Reading the temporary .xlsx file in R:
dataf <- read_excel(tf)
# Checkiing dataframe:
head(dataf)Code language: R (r)
A quick note before going on to the third example is that readxl and dplyr, a package we will use later, are part of the Tidyverse package. If you install Tidyverse you will get some powerful tools to extract year from date in R, carry out descriptive statistics, visualize data (e.g., scatter plots with ggplot2), to name a few.
3: How to use the %in% Operator in R to Test if Value is in Column
In this example, we will look at a straightforward example of how to use this operator. Namely, we are going to use %in% to check if a value is in one of the columns in a dataframe:
# %in% column
2 %in% dataf$boatCode language: R (r)If you have read through the first two examples, you already know we get a boolean vector. In this vector, the value TRUE means that the cell contained the value we sought. Notice also how we used the $ operator to select one of the columns.
4: Using %in% in R to Add a New Column to a Dataframe
Here is how to use the %in% operator to create a new variable:
# Creating a dataframe:
dataf2 <- data.frame(Type = c("Fruit","Fruit","Fruit","Fruit","Fruit",
"Vegetable", "Vegetable", "Vegetable", "Vegetable", "Fruit"),
Name = c("Red Apple","Strawberries","Orange","Watermelon","Papaya",
"Carrot","Tomato","Chili","Cucumber", "Green Apple"),
Color = c(NA, "Red", "Orange", "Red", "Green",
"Orange", "Red", "Red", "Green", "Green"))
# Adding a New Column:
dataf2 <- within(dataf2, {
Red_Fruit = "No"
Red_Fruit[Type %in% c("Fruit")] = "No"
Red_Fruit[Type %in% "Vegetable"] = "No"
Red_Fruit[Name %in% c("Red Apple", "Strawberries", "Watermelon", "Chili", "Tomato")] = "Yes"
})Code language: R (r)Notice how we make use of the operator. Here is the dataframe, with the added column “Red_Fruit”:
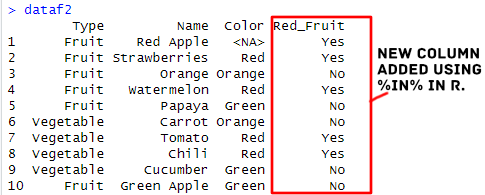
In another post, you will learn how to use R to add a column to a dataframe based on conditions and/or values in other columns.
5: Utilizing the %in% in R to Subset Data
In this example, we are going to use the %in% operator to subset the data:
library(dplyr)
home.dests <- c("St Louis, MO", "New York, NY", "Hudson, NY")
# Subsetting using %in% in R:
dataf %>%
filter(home.dest %in% home.dests)Code language: R (r)Notice how we created a vector of the elements we want to include in our new, subsetted dataframe. Furthermore, we also used the dplyr package and the filter() function together with the %in% operator. Finally, we get the resulting subsetted dataframe:

Note dplyr comes with many other handy functions, such as the select-family. For example, you can use dplyr to select columns in R or to take the absolute value in R, using the function only on numerical columns. In the next section, we will look at another way to use the %in% operator: to drop columns from a dataframe.
6: Add a Column using %in% in R
Here, we make use of the mutate() function together with the %in% operator in R:
dataf2 %>%
mutate(Red_fruit = if_else(
Color %in% "Red" & Type == "Fruit", "Yes","No"))Code language: JavaScript (javascript)In the code chunk above, we are using the %>% operator to perform a sequence of operations on the dataf2 data frame. Specifically, we are using the mutate() function to add a new column called Red_fruit to dataf2.
Next, within the mutate() function, we are using the if_else() function to determine whether each row of dataf2 corresponds to a red fruit.
In this case, the logical condition is given by Color %in% "Red" & Type == "Fruit", which checks whether the Color column contains the value “Red” and the Type column contains the value “Fruit”. If the condition is TRUE, the value “Yes” is returned, indicating that the row corresponds to a red fruit. If the condition is FALSE, the value “No” is returned instead.
The %in% operator is used to check whether each column element is equal to “Red”. It returns a logical vector indicating whether each element is a member of the set { “Red” }.
7: Using %in% in R to Remove Columns from Dataframe
In this example, we are going to use %in% to drop columns from the datafarme:
# Drop columns using %in% operator in R
dataf[, !(colnames(dataf) %in% c("pclass", "embarked", "boat"))]Code language: R (r)In the code chunk above, we used the I to tell R that we do not want to select these columns. Running the code, above will result in a new dataframe with the columns removed:

Note it is also possible to use dplyr to remove columns in R. For example, using the select() function with the pipe operator may result in a slightly more readable code.
In the following example, we are going to have a look at how we can use the %in% operator to do the opposite of dropping columns. That is, we are going to select columns instead.
8: Make use of the %in% Operator to Select Columns
Let us use the %in% operator to select several variables from the dataframe:
# Select columns using %in%:
dataf[, (colnames(dataf) %in% c("pclass", "embarked", "boat"))]Code language: CSS (css)Note that we removed the ! before the parentheses, which will tell R to select these columns (see example 6 above for the opposite).
Selecting columns instead of deleting them might be a more efficient way to go if we have a lot of variables in our dataset and we want to create a new dataframe with only some of them. Notice how we used another nice function: select_if(). This function, also from the dplyr package, allows us to select columns based on their names.
In the final bonus section, we will see how to negate the %in% operator. Now, we will do this because there is no built-in “not in” operator in R.
Bonus: Creating a not in operator in R
Here is how we can create our own not in operator in R:
# Creating a not in operator:
`%notin%` <- Negate(`%in%`)Code language: R (r)Pretty simple. It is now possible to use this new R not in operator to check if, e.g., a number is not in a vector:
# Generating a sequence of numbers:
numbs <- rep(seq(3), 4)
# Using the not in operator:
4 %notin% numbs
# Output: [1] TRUECode language: R (r)As you can see in the example above, we can use the %notin% operator similarly to the %in% operator. Note that it is also possible to use both operators on lists. Finally, it is worth noting that some R packages contain “not in” functions. For example, package mefa4 has the %notin% function. See the recent post about selecting and filtering values not in R’s dataframe.
Conclusion: R in operator
In summary, %in% is an operator in R that compares two sequences of values and returns a logical vector indicating which elements of the first sequence are also present in the second sequence. The %in% operator differs from the == operator, which compares individual values. Moreover, the %in% operator has several use cases, such as testing if a value is in a column, adding a new column to a dataframe, subsetting data, and selecting columns. Additionally, a not in operator can be created by negating the %in% operator with the ! operator. Overall, the %in% operator is a powerful tool in R for data manipulation and analysis.
R Tutorials
Here are some other useful tutorials:
- How to Rename Column (or Columns) in R with dplyr
- Select Columns in R by Name, Index, Letters, & Certain Words with dplyr
- How to Extract Year from Date in R with Examples
- Learn How to Calculate Descriptive Statistics in R the Easy Way
- How to Create a Word Cloud in R
- How to Extract Day from Datetime in R with Examples
- Learn How to Create Dummy Variables in R (with Examples)

In the example `which(seq(1:10) %in% seq(4:12))` you probably meant `which(1:10 %in% 4:12)` without the `seq`. The former works too, but gives `1 2 3 4 5 6 7 8 9`, while the latter gives `4 5 6 7 8 9 10` (which is what most people would expect).
Hey Elmar,
Thanks for your comment. You are right. I was probably a bit quick when writing some of the examples. I have now corrected the code chunk,
Erik