In this Pandas tutorial, we are going to learn 1) how to read SPSS (.sav) files in Python, and 2) how to write to SPSS (.sav) files using Python.
Python is a great general-purpose language as well as for carrying out statistical analysis and data visualization. However, Python is not really user-friendly when it comes to data storage. Thus, often our data will be archived using Excel, SPSS or similar software.
For example, learn how to import data from other file types, such as Excel, SAS, and Stata in the following two posts:
- Read SAS files in Python using Pandas
- Read Excel (.xslx) files in Python with Pandas
- How to read Stata files in Python with Pandas and Pyreadstat
If we ever need to learn how to read a file in Python in other formats, such a text file, it is doable. To read a file in Python without any libraries we just use the open() method.
Table of Contents
- How to Open an SPSS file in Python with Pandas in 2 Steps:
- How to install Pyreadstat:
- How to Load a .sav File in Python Using Pyreadstat
- How to Write an SPSS file Using Python
- Summary: Read and Write .savn Files in Python
- Resources
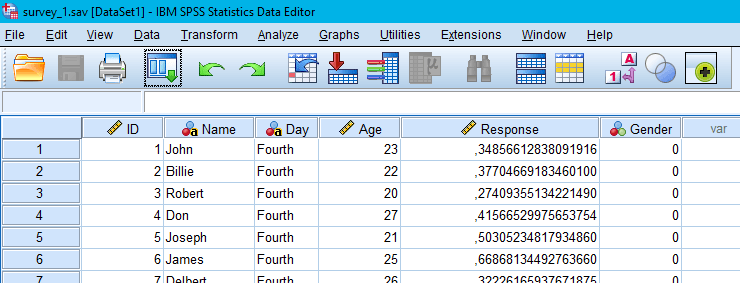
How to open a .sav file in Python? There are some packages as Pyreadstat, and Pandas, that allow performing this operation. If we work with Pandas, the read_spss method will load a .sav file into a Pandas dataframe. Note, Pyreadstat will also create a Pandas dataframe from an SPSS file.
How to Open an SPSS file in Python with Pandas in 2 Steps:
Time needed: 1 minute
Here are two simple steps on how to read .sav files in Python using Pandas (more details will be provided in this post):
- import pandas
in your script type “import pandas as pd“

- use read_spss
in your script use the read_spss method:
df = read_spss(‘PATH_TO_SAV_FILE”)
In this section, we are going to learn how to load an SPSS file in Python using the Python package Pyreadstat. Before we use Pyreadstat we are going to install it. This Python package can be installed in two ways.
How to install Pyreadstat:
There are two very easy methods to install Pyreadstat.:
- Install Pyreadstat using pip:
Open up a terminal, or windows command prompt, and type pip install pyreadstat - Install using Conda:
Open up a terminal, or windows command prompt and type conda install -c conda-forge pyreadstat
Note, Pandas can be installed by changing “pyreadstat” to “pandas”. Furthermore, it’s also possible to install & update Python packages using Anaconda Navigator.
How to Load a .sav File in Python Using Pyreadstat
Every time we run our Jupyter notebook, we need to load the packages we need. In the Python read SPSS example below, we will use Pyreadstat and, thus, the first line of code will import the package:
Step 1: Import pyreadstat
# 1: import the pyreadstat package
import pyreadstatCode language: Python (python)Step 2: Use read_sav to import data:
Now, we can use the method read_sav to read an SPSS file. Note that, when we load a file using the Pyreadstat package, recognize that it will look for the file in Python’s working directory. In the read SPSS file in Python example below, we are going to use this SPSS file. Make sure to download it and put it in the correct folder (or change the path in the code chunk below):
# 2 use read_sav to read SPSS file:
df, meta = pyreadstat.read_sav('./SimData/survey_1.sav')Code language: Python (python)In the code chunk above we create two variables; df, and meta. As can be seen, when using type df is a Pandas dataframe:
type(df)Code language: Python (python)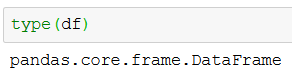
Thus, we can use all methods available for Pandas dataframe objects. In the next line of code, we are going to print the 5 first rows of the dataframe using pandas head method.
df.head()Code language: Python (python)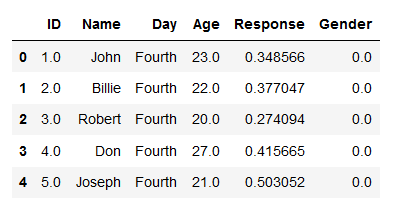
See more about working with Pandas dataframes in the following tutorials:
- Python Groupby Tutorial: Here you will learn about working the groupby method to group Pandas dataframes.
- Learn how to take random samples from a pandas dataframe
- A more general, overview, of how to work with Pandas dataframe objects can be found in the Pandas Dataframe tutorial.
How to Read an SPSS file in Python Using Pandas
Pandas can, of course, also be used to load an SPSS file into a dataframe. Note, however, we need to install the Pyreadstat package as, at least right now, Pandas depends on this for reading .sav files. As always, we need to import Pandas as pd:
import pandas as pdCode language: Python (python)Now, when we have done that, we can read the .sav file into a Pandas dataframe using the read_spss method. In the read SPSS example below, we read the same data file as earlier and print the 5 last rows of the dataframe using Pandas tail method. Remember, using this method also requires you to have the file in the subfolder “simData” (or change the path in the script).
df = pd.read_spss('./SimData/survey_1.sav')
df.tail()Code language: Python (python)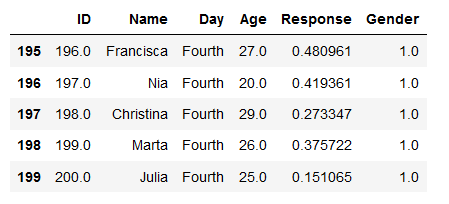
Reading Specific Columns from the .sav File in Python
Note, that both read_sav (Pyreadstat) and read_spss have the arguments “usecols”. By using this argument, we can also select which columns we want to load from the SPSS file to the dataframe:
cols = ['ID', 'Day', 'Age', 'Response', 'Gender']
df = pd.read_spss('./SimData/survey_1.sav', usecols=cols)
df.head()Code language: Python (python)
Now, that we know how to read data from a .sav file using Python, Pyreadstats, and Pandas we can explore the data. For example, there are many libraries in Python for data visualisation and we can continue by making a Seaborn scatter plot.
How to Write an SPSS file Using Python
Now we are going to learn how to save Pandas dataframe to an SPSS file. It’s simple, we will use the Pyreadstats write_sav method. The first argument should be the Pandas dataframe that is going to be saved as a .sav file.
pyreadstat.write_sav(df, './SimData/survey_1_copy.sav')Code language: Python (python)Remember to put the right path, as the second argument, when using write_sav to save a .sav file.
Unfortunately, Pandas don’t have a to_spss method, yet. But, as Pyreadstats is a dependency of Pandas read_spss method we can use it to write an SPSS file in Python.
Summary: Read and Write .savn Files in Python
Now we have learned how to read and write .sav files using Python. It was quite simple and both methods are, in fact, using the same Python packages.
Here’s a Jupyter notebook with the code used in this Python SPSS tutorial.
Resources
Here are some Python tutorials you may find helpful:
- Coefficient of Variation in Python with Pandas & NumPy
- How to Perform Mann-Whitney U Test in Python with Scipy and Pingouin
- Find the Highest Value in Dictionary in Python
- Python Scientific Notation & How to Suppress it in Pandas & NumPy
- Wilcoxon Signed-Rank test in Python

So helpful! I just downloaded R in order to open an .sav file. Now that I’ve read this, I’ll be able to open .sav files right in Python!
Hey Andrea. Thanks for your comment. I am glad that you found this post useful.
/Erik
Hello Erik. This blog solved a huge problem of mine. Trying to read an SPSS file (.sav) using Python to display the value labels coming from the meta data. For example, in your case, listing the gender as male and female instead of 1.0 and 2.0.
Thanks again for this post.
Hey Fatih,
I am glad to hear that it helped you solve your problems,
Best,
Erik
Thank you verymuch
Glad I could help!