In this Pandas tutorial, we are going to learn how to read Stata (.dta) files in Python.
As previously described (in the read .sav files in Python post) Python is a general-purpose language that also can be used for doing data analysis and data visualization. One example of data visualization will be found in this post.
One potential downside, however, is that Python is not really user-friendly for data storage. This has, of course, lead to that our data many times are stored using Excel, SPSS, SAS, or similar software. See, for instance, the posts about reading .sav, and sas files in Python:
Table of Contents
- Can I Open a Stata File in Python?
- How to Load a Stata File in Python Using Pyreadstat in Two Steps
- How to Read a Stata file with Python Using Pandas in Two Steps
- How to Read .dta Files from URL
- How to Read Specific Columns from a Stata file
- How to Save a Stata file
- Save a CSV file as a Stata File
- Export an Excel file as a Stata File
- Summary: Read Stata Files using Python
Can I Open a Stata File in Python?
We are soon going to practically answer how to open a Stata file in Python? In Python, there are two useful packages called Pyreadstat, and Pandas that enable us to open .dta files. If we are working with Pandas, the read_stata method will help us import a .dta into a Pandas dataframe. Furthermore, the package Pyreadstat, which is dependent on Pandas, will also create a Pandas dataframe from a .dta file.
How to install Pyreadstat:
First, before learning how to read .dta files using Python and Pyreadstat we need to install it. Like many other Python packages this package can be installed using pip or conda:
- Install Pyreadstat using pip:
Open up the Windows Command Prompt and typepip install pyreadstat
- Install using Conda:
Open up the Anaconda Prompt, and typeconda install -c conda-forge pyreadstat
In the next section, we are finally ready to learn how to read a .dta file in Python using the Python packages Pyreadstat and Pandas.
How to Load a Stata File in Python Using Pyreadstat in Two Steps
In this section, we are going to use pyreadstat to import a .dta file into a Pandas dataframe.
Step 1: Import the pyreadstat package
First, we import pyreadstat:
import pyreadstatCode language: Python (python)Step 2: Import the .dta File using read_dta
Second, we are ready to import Stata files using the method read_dta. Note that, when we load a file using the Pyreadstat package, it will look for the .dta file in Python’s working directory. In the read Stata files example below, the FifthDaydata.dta is located in a subdirectory (i.e., “SimData”).
dtafile = './SimData/FifthDayData.dta'
df, meta = pyreadstat.read_dta(dtafile)Code language: Python (python)In the code chunk above, two variables were created; df, and meta. If we use the Python function type we can see that “df” is a Pandas dataframe:

This means that we can use all the available methods for Pandas dataframe objects. In the next line of code, we are Pandas head method to print the first 5 rows.
df.head()Code language: Python (python)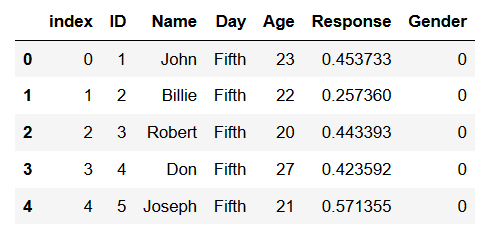
Learn more about working with Pandas dataframes in the following tutorials:
- Python Groupby Tutorial: Here you will learn about working the groupby method to group Pandas dataframes.
- Learn how to take random samples from a pandas dataframe
- A more general, overview, of how to work with Pandas dataframe objects can be found in the Pandas Dataframe tutorial.
How to Read a Stata file with Python Using Pandas in Two Steps
In this section, we are going to read the same Stata file into a Pandas dataframe. However, this time we will use Pandas read_stata method. This has the advantage that we can load the Statafile from a URL.
Step 1: Import Pandas
In the first step, we import Pandas:
import pandas as pdCode language: Python (python)Step 2: Read the .dta File
Now, when we have imported pandas that, we can read the .dta file into a Pandas dataframe using the read_stata method. Here’s how to import a Stata file with Pandas read_stata() method:
dtafile = './SimData/FifthDayData.dta'
df = pd.read_stata(dtafile)
df.tail()Code language: Python (python)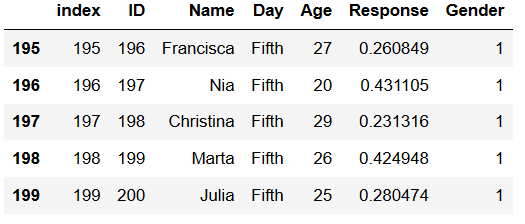
After we have loaded the Stata file using Python Pandas, we printed the last 5 rows of the dataframe with the tail method (see image above).
How to Read .dta Files from URL
In this section, we are going to use Pandas read_stata method, again. However, this time we will read the Stata file from a URL.
url = 'http://www.principlesofeconometrics.com/stata/broiler.dta'
df = pd.read_stata(url)
df.head()Code language: Python (python)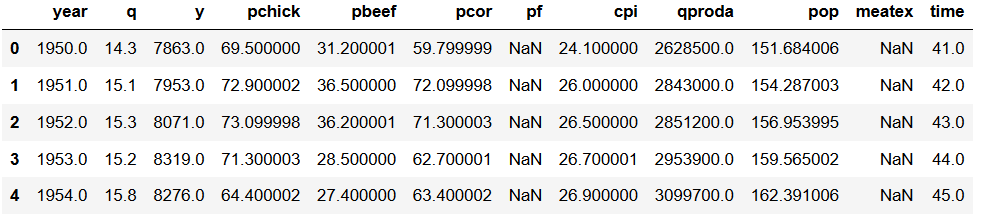
Note, the only thing we changed was we used a URL as input (url) and Pandas read_stata will import the .dta file that the URL is pointing to. Now that the data is loaded, you can go on by adding data to new columns in the dataframe.
Pandas Scatter Plot
Here, we will create a scatter plot in Python using Pandas scatter method. This is to illustrate how we can work with data imported from .dta files.
df.plot.scatter(x='pchick',
y='cpi')Code language: JavaScript (javascript)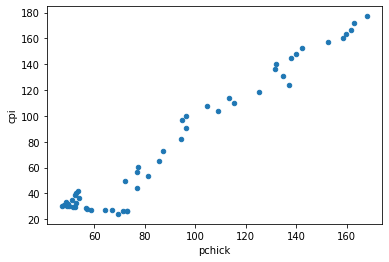
Learn more about data visualization in Python:
- How to Make a Scatter Plot in Python using Seaborn
- 9 Data Visualization Techniques You Should Learn in Python
How to Read Specific Columns from a Stata file
Now using pyreadstat read_dta and Pandas read_staat both enables us to read specific columns from a Stata file. Note, that read_dta have the argument usecols and Pandas the argument columns.
Method 1: Reading Specific Columns using Pyreadstat
In this Python read dta example, we use the argument usecols that takes a list as parameter.
import pyreadstat
dtafile = './SimData/FifthDayData.dta'
df, meta = pyreadstat.read_dta(dtafile,
usecols=['index', 'Name', 'ID',
'Gender'])
df.head()Code language: Python (python)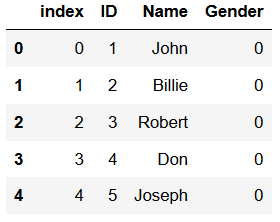
Method 2: Reading Specific Columns using Pandas read_stata
Here, we are going to use Pandas read_stata method and the argument columns. This argument, as in the example above, takes a list as input.
import pandas as pd
url = 'http://www.principlesofeconometrics.com/stata/broiler.dta'
df = pd.read_stata(url,
columns=['year', 'pchick', 'time',
'meatex'])
df.head()Code language: Python (python)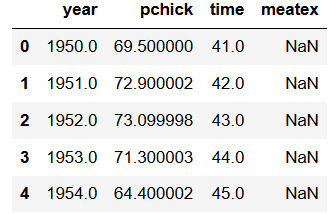
Note, the behavior of Pandas read_stata; in the resulting dataframe the order of the column will be the same as in the list we put in.
How to Save a Stata file
In this section of the Python Stata tutorial, we are going to save the dataframe as a .dta file. This is easily done, we just have to use the write_dta method when using Pyreadstat and the dataframe method to_stata in Pandas.
Saving a dataframe as a Stata file using Pyreadstat
In the example below, we are using the dataframe we created in the previous section and write it as a dta file.
pyreadstat.write_dta(df, 'broilerdata_edited.dta')Code language: Python (python)
Now, between the parentheses is where the important stuff happens. The first argument is our dataframe and the second is the file path. Note, only having the filename, as in the example above, will make the write_dta method to write the Stata file to the current directory.
How to Save a dataframe as .dta with Pandas to_stata
In this example, we are going to save the same dataframe using Pandas to_stata:
df.to_stata('broilerdata_edited.dta')Code language: Python (python)
As can be seen in the image above, the dataframe object has the to_stata method. Within, the parentheses we put the file path.
Save a CSV file as a Stata File
In this section, we are going to work with Pandas read_csv to read a CSV file, containing data. After we have imported the CSV to a dataframe we are going to save it as a .dta file using Pandas to_stat:
df = pd.read_csv('./SimData/FifthDayData.csv')
df.to_stata('./SimData/FifthDayData.dta')Code language: Python (python)Export an Excel file as a Stata File
In the final example, we are going to use Pandas read_excel to import a .xslx file and then save this dataframe as a Stata file using Pandas to_stat:
df = pd.read_excel('./SimData/example_concat.xlsx')
df.to_stata('./SimData/example_concat.dta')Code language: Python (python)Note, that in both of the last two examples above we save the data to a folder called SimData. If we want to save the CSV and Excel file to the current directory we simply remove the “./SimData/” part of the string.
Learn more about importing data using Pandas:
Note, all the files we have read using read_dta, read_stata, read_csv, and read_excel can be found here and a Jupyter Notebook here. It is, of course, possible to open SPSS and SAS files using Pandas and save them as .dta files as well.
Summary: Read Stata Files using Python
In this post, we have learned how to read Stata files in Python. Furthermore, we have learned how to write Pandas dataframes to Stata files.
