Data visualization is a big part of the process of data analysis. In this post, we will learn how to make a scatter plot using Python and the package Seaborn. In detail, we will learn how to use the Seaborn methods scatterplot, regplot, lmplot, and pairplot to create scatter plots in Python.
- If you are interested in learning about more Python data visualization methods see the post “9 Data Visualization Techniques You Should Learn in Python“.
More specifically, we will learn how to make scatter plots, change the size of the dots, change the markers, the colors, and change the number of ticks. Furthermore, we will learn how to plot a regression line, add text, plot a distribution on a scatter plot, among other things. Finally, we will also learn how to save Seaborn plots in high resolution. That is, we learn how to make print-ready plots.
- In a more recent post, Seaborn line plots: a detailed guide with examples (multiple), we learn how to use the lineplot method.
Scatter plots are powerful data visualization tools that can reveal a lot of information. Thus, this Python scatter plot tutorial will start to explain what they are and when to use them. After that, we will learn how to make scatter plots.
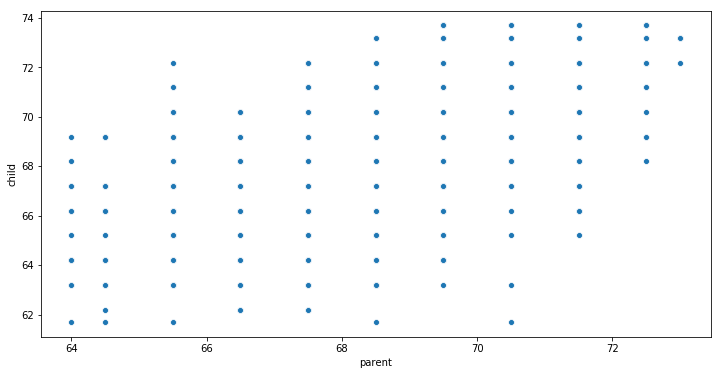
Table of Contents
- Python Scatter Plot Tutorial
- How to use Seaborn to create Scatter Plots in Python
- Seaborn Scatter plot using the scatterplot method
- How to Change the Size of the Dots
- How to Change the Axis
- Grouped Scatter Plot in Seaborn using the hue Argument
- Changing the Markers (the dots)
- Add a Bivariate Distribution on a Seaborn Scatter plot
- Seaborn Scatter plot using the regplot method
- Scatter Plot Without Confidence Interval
- Seaborn regplot Without Regression Line
- Changing the Number of Ticks
- Changing the Color on the Scatterplot
- Adding Text to a Seaborn Plot
- Seaborn Scatter Plot with Trend Line and Density
- How to Rotate the Axis Labels on a Seaborn Plot
- Scatter Plot Using Seaborn lmplot Method
- Changing the Color Using the Palette Argument
- Change the Markers on the lmplot
- Seaborn Pairplot: Scatterplot + Histogram
- Pairplot with Grouped Data
- Saving a High-Resolution Plot in Python
- Conclusion
- References
To make a scatter plot in Python, you can use Seaborn and the scatterplot() method. For example, if you want to examine the relationship between the variables “Y” and “X” you can run the following code: sns.scatterplot(Y, X, data=dataframe). There are, of course, several other Python packages that enable you to create scatter plots. For example, Pandas have methods in the DataFrame object that enables us to create plots.
To change the size of the scatter plot, you can, for example, use the set_size_inches() method. Note, this involves importing the Python package matplotlib so this method can be used, whether using ,e.g., Seaborn or Pandas when creating your scatter plot. If you want to change the size of the dots, you can learn this in a section of this post.
An example scatter plot shows the relationship between two variables (child and parent). This plot was created using Seaborn.
Note, there are of course possible to create a scatter plot with other programming languages, or applications. In this post, we focus on how to create a scatter plot in Python, but the user of R statistical programming language can look at the post on how to make a scatter plot in R tutorial.
Python Scatter Plot Tutorial
This is exactly what we are going to learn in this tutorial; how to make a scatter plot using Python and Seaborn.
In the first code chunk, below, we are importing the packages we are going to use. Furthermore, to get data to visualize (i.e., create scatter plots) we load this from a URL. Note, the %matplotlib inline code is only needed if we want to display the scatter plots in a Jupyter Notebook. This is also the case for the import warnings and warnings.filterwarnings(‘ignore’) part of the code.
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
# Suppress warnings
import warnings
warnings.filterwarnings('ignore')
# Import Data from CSV
data = 'https://vincentarelbundock.github.io/Rdatasets/csv/datasets/mtcars.csv'
# Reading the CSV from the URL:
df = pd.read_csv(data, index_col=0)
# Printing the first 6 rows:
df.head()Code language: Python (python)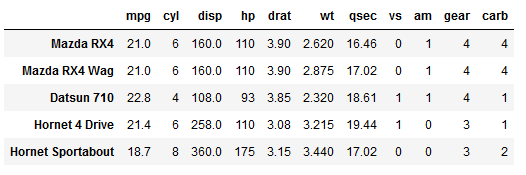
Now, in the code chunk above, we first used the %matplotlib inline so that the plots will show up in a Jupyter Notebook. This means this line is optional if you are not using a Notebook. Second, the next 4 lines of codes, involves importing the Python libraries used in this post. Again, if you only are going to create scatter plots you may only need Pandas and Seaborn (maybe only Seaborn). Notice how we also import warnings and suppress them.
Finally, we are ready to import an example dataset to play around with. First, we created a string variable containing an URL. Second, we used Pandas read_csv method to load data into a dataframe. Notice how we also used the index_col parameter to tell the method that the first column, in the .csv file, is the index column.
If you want to find out more you can see the Pandas Read CSV Tutorial. If you want to load the data from the web (e.g., parse HTML tables or JSON files):
- How to Read and Write JSON Files using Python and Pandas
- Exploratory Data Analysis in Python Using Pandas, SciPy, and Seaborn (read_html examples)
- Working with Excel Files: Pandas Excel Tutorial: How to Read and Write Excel files
How to use Seaborn to create Scatter Plots in Python
In this section, we will learn how to make scatter plots using Seaborn’s scatterplot, regplot, lmplot, and pairplot methods.
Seaborn Scatter plot using the scatterplot method
First, we start with the most obvious method to create scatter plots using Seaborn: using the scatterplot method. In the first Seaborn scatter plot example, below, we plot the variables wt (x-axis) and mpg (y-axis). This will give us a simple scatter plot:
# Creating the scatter plot with seaborn:
sns.scatterplot(x='wt', y='mpg', data=df)Code language: Python (python)- If we need to specify the size of a scatter plot a newer post will teach us how to change the size of a Seaborn figure.
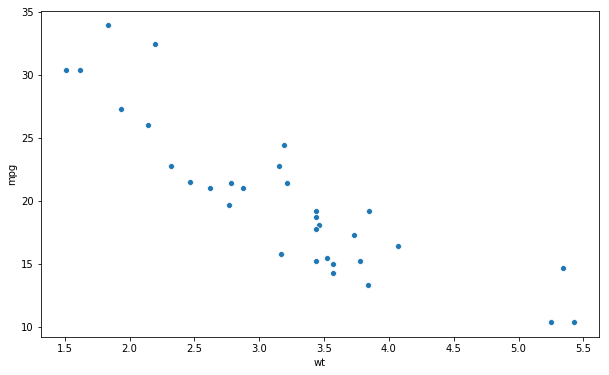
That was rather simple, right? The scatterplot method takes a number of parameters and we used the x and y, to show the relationship between the wt and mpg variables found in the dataframe (data=df). In the next example, you will learn how to create a scatter plot and change the size of the dots.
How to Change the Size of the Dots
If we want to have the size of the dots represent one of the variables this is possible. So, how do you change the size of the dots in a Seaborn plot? In the next example, we change the size of the dots using the size argument.
# Changing dot size seaborn scatter plot
sns.scatterplot(x='wt', y='mpg',
size='wt', data=df)Code language: PHP (php)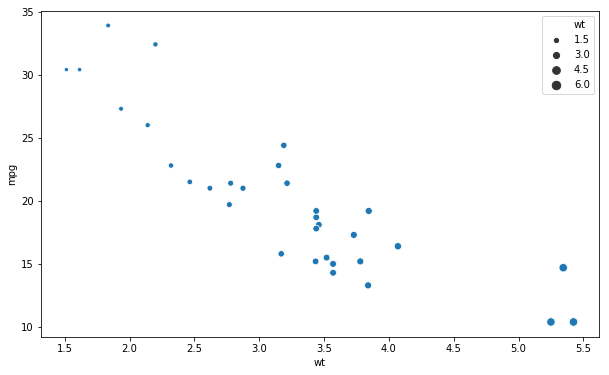
How to Change the Axis
In the next Seaborn scatter plot example we are going to learn how to change the ticks on the x- and y-axis’. That is, we are going to change the number of ticks on each axis. To do this we use the set methods and use the arguments xticks and yticks:
ax = sns.scatterplot(x='wt', y='mpg', size='wt', data=df)
# Modifying the number of ticks of the seaborn scatter plot:
ax.set(xticks=np.arange(1, 6, 1),
yticks=np.arange(5, 50, 10))Code language: PHP (php)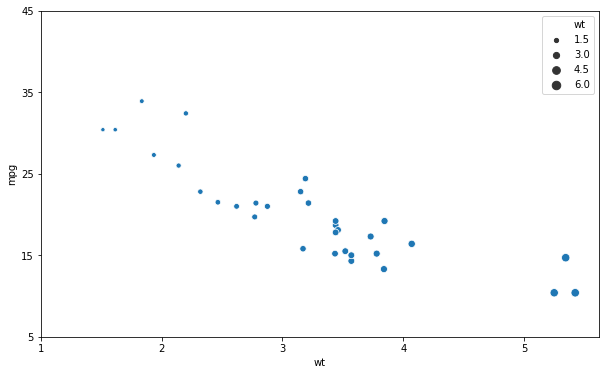
Grouped Scatter Plot in Seaborn using the hue Argument
If we have a categorical variable (i.e., a factor) and want to group the dots in the scatter plot we use the hue argument:
# seaborn scatter plot hue:
sns.scatterplot(x='wt', y='mpg',
hue='vs', data=df)Code language: PHP (php)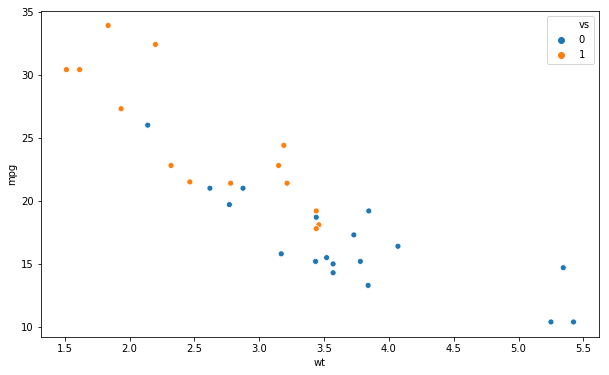
There is, of course, possible to group the data using Pandas groupby method. If you are interested in learning more about working grouping data using Pandas:
Changing the Markers (the dots)
Now, one way to change the look of the markers is to use the style argument.
data = 'https://vincentarelbundock.github.io/Rdatasets/csv/carData/Burt.csv'
df = pd.read_csv(data, index_col=0)
sns.scatterplot(x='IQbio', y='IQfoster', style='class',
hue='class', data=df)Code language: JavaScript (javascript)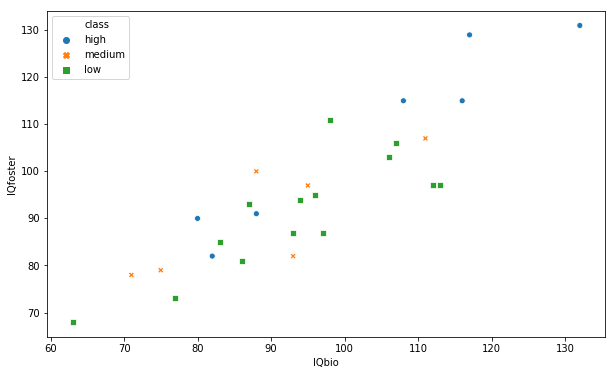
Note, should also be possible to use the markers argument. However, it seems not to work, right now.
Add a Bivariate Distribution on a Seaborn Scatter plot
In the next Seaborn scatter plot example we are going to plot a bivariate distribution on top of our scatter plot. This is quite simple and after we have called the scatterplot method we use the kdeplot method:
data = 'https://vincentarelbundock.github.io/Rdatasets/csv/datasets/mtcars.csv'
df = pd.read_csv(data, index_col=0)
# 1 create the scatter plot
sns.scatterplot(x='wt', y='mpg', data=df)
# 2 add the bivariate distribution plot:
sns.kdeplot(df.wt, df.mpg)Code language: PHP (php)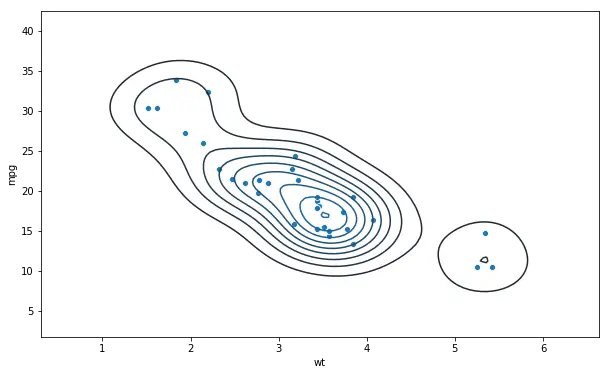
Seaborn Scatter plot using the regplot method
If we want a regression line (trend line) plotted on our scatter plot we can also use the Seaborn method regplot. In the first example, using regplot, we are creating a scatter plot with a regression line. Here, we also get the 95% confidence interval:
# Seaborn Scatter Plot with Regression line and CI:
sns.regplot(x='wt', y='mpg',
data=df)Code language: Python (python)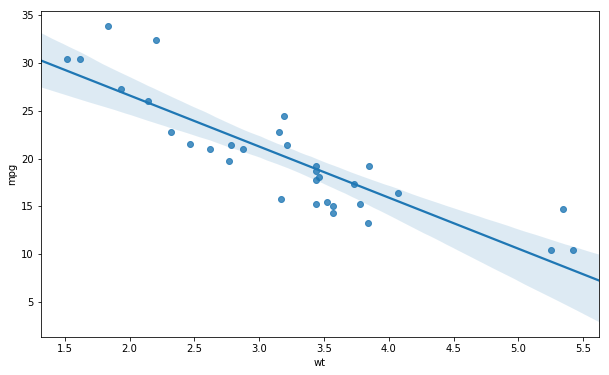
Scatter Plot Without Confidence Interval
We can also choose to create a scatter plot without the confidence interval. This is simple, we just add the ci argument and set it to None.
# Seaborn Scatter Plot with Regression line:
sns.regplot(x='wt', y='mpg',
ci=None, data=df)Code language: Python (python)This will result in a scatter plot with only a regression line:
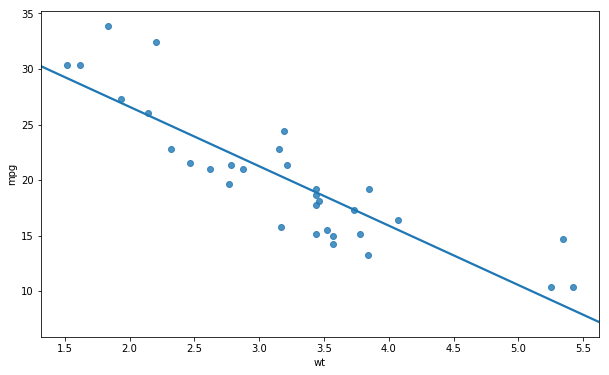
Note, if we want to change the confidence interval we can just change the ci=None to ci=70.
Seaborn regplot Without Regression Line
Furthermore, it’s possible to create a scatter plot without the regression line using the regplot method. In the next example, we just add the argument reg_fit and set it to False:
sns.regplot(x='wt', y='mpg',
fit_reg=False, ci=None, data=df)Code language: Python (python)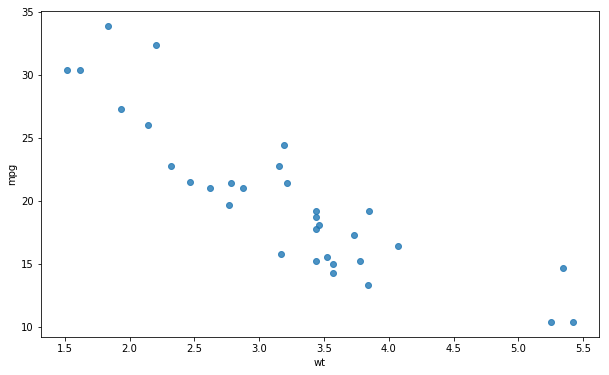
Changing the Number of Ticks
It’s also possible to change the number of ticks when working with Seaborn regplot. In fact, it’s as simple as working with the scatterplot method, we used earlier. To change the ticks we use the set method and the xticks and yticks arguments:
# creating the scatter plot:
ax = sns.regplot(x='wt', y='mpg', data=df)
# Changing the ticks of the scatter plot:
ax.set(xticks=np.arange(1, 6, 1),
yticks=np.arange(5, 50, 10))Code language: Python (python)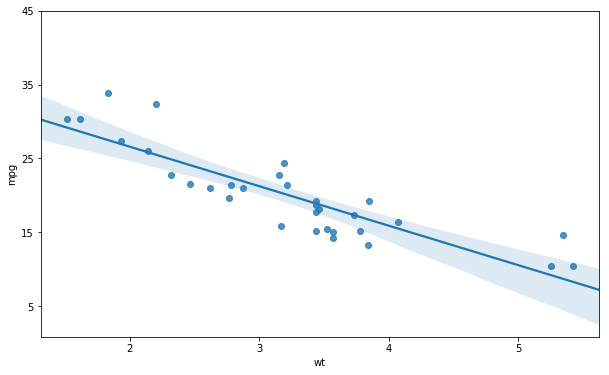
Changing the Color on the Scatterplot
If we want to change the color of the plot, it’s also possible. We just have to use the color argument. In the regplot example below we are getting a green trend line and green dots:
# Changing color on the scatter plot:
sns.regplot(x='wt', y='mpg',
color='g', data=df) Code language: Python (python)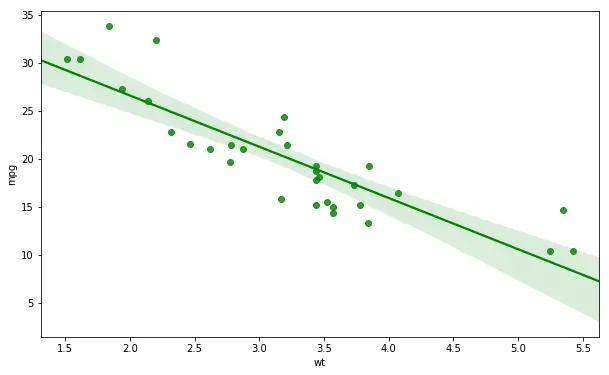
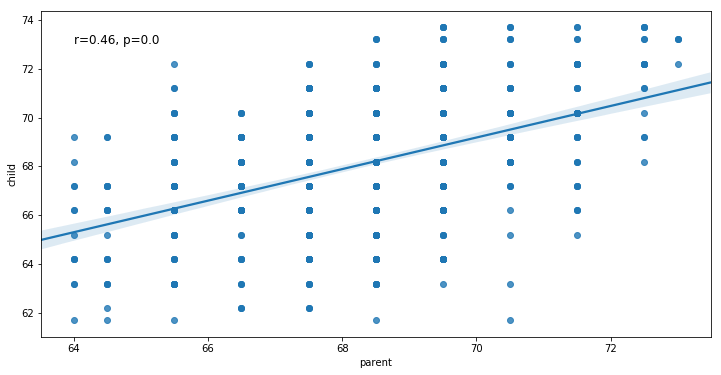
Adding Text to a Seaborn Plot
In the next example, we are going to learn how to add text to a Seaborn plot. Remember the plot, in the beginning, showing the relationship between children’s height and their parent’s height? In that plot, there was a regression line as well as the correlation coefficient and p-value. Here we are going to learn how to add this to a scatter plot. First, we start by using pearsonr to calculate the correlation between the variables wt and mpg:
from scipy.stats import pearsonr
# Pearson correlation with SciPy:
corr = pearsonr(df['wt'], df['mpg'])
corr = [np.round(c, 2) for c in corr]
print(corr)
# Output: [-0.87, 0.0]Code language: PHP (php)In the next code chunk, we are creating a string variable getting our Pearson r and p-value (corr[0] and corr[1], respectively). Next, we create the scatter plot with the trend line and, finally, add the text. Note, the first two arguments are the coordinates where we want to put the text:
# Extracting the r-value and the p-value:
text = 'r=%s, p=%s' % (corr[0], corr[1])
# Creating the regression plot:
ax = sns.regplot(x="wt", y="mpg", data=df)
# Adding the text to the Seaborn plot:
ax.text(4, 30, text, fontsize=12)Code language: Python (python)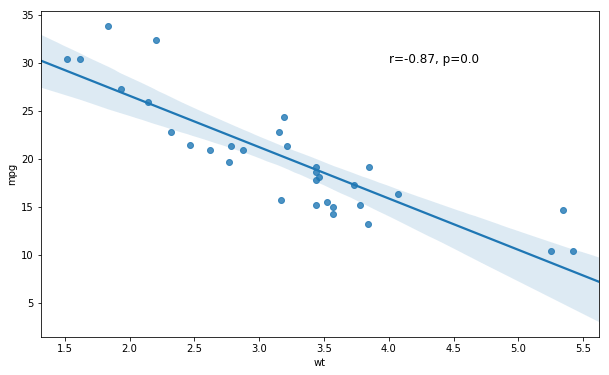
Seaborn Scatter Plot with Trend Line and Density
It’s, of course, also possible to plot a bivariate distribution on the scatter plot with a regression line. In the final example, using Seaborn regplot we just add the kernel density estimation using Seaborn kde method:
import seaborn as sns
# Creating the scatter plot with regression line:
sns.regplot(x='wt', y='mpg',
ci=None, data=df)
# Adding the distribution plot:
sns.kdeplot(df.wt, df.mpg)Code language: Python (python)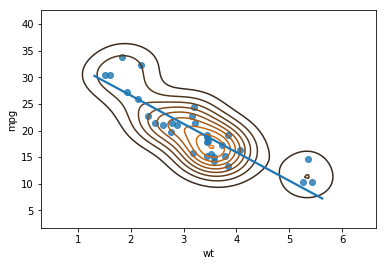
How to Rotate the Axis Labels on a Seaborn Plot
If the labels on the axis’ are long, we may want to rotate them for readability. It’s quite simple to rotate the axis labels on the regplot object. Here we rotate labels on the x-axis 90 degrees:
ax = sns.regplot(x='wt', y='mpg', data=df)
# Rotating the axis on the Seaborn plot:
for item in ax.get_xticklabels():
item.set_rotation(90)Code language: PHP (php)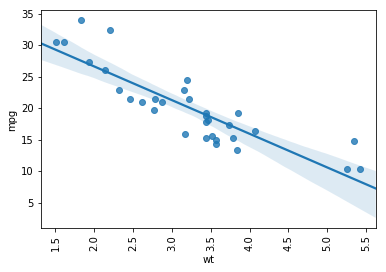
Scatter Plot Using Seaborn lmplot Method
In this section, we are going to cover Seaborn’s lmplot method. This method enables us to create grouped Scatter plots with a regression line.
In the first example, we are just creating a Scatter plot with the trend lines for each group. Note, here we use the argument hue to set what variable we want to group by.
# Scatter plot grouped with Seaborn lmplot:
sns.lmplot(x='wt', y='mpg',
hue='vs', data=df)Code language: Python (python)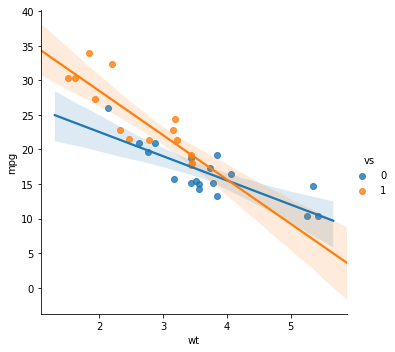
Changing the Color Using the Palette Argument
When working with Seaborn’s lmplot method we can also change the color of the lines, CIs, and dots using the palette argument. See here for different palettes to use.
# Changing the Color of a Seaborn Plot:
sns.lmplot(x='wt', y='mpg', hue='vs',
palette="Set1", data=df)Code language: Python (python)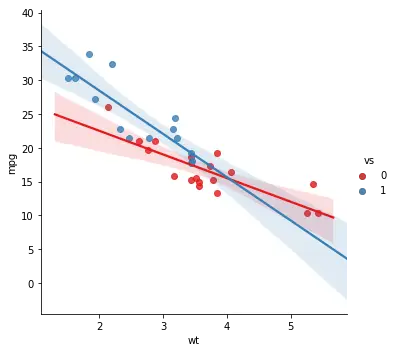
Change the Markers on the lmplot
As previously mentioned, when creating scatter plots, the markers can be changed using the markers argument. In the next Seaborn lmplot example we are changing the markers to crosses:
sns.lmplot(x='wt', y='mpg',
hue='vs', palette="Set1", markers='+', data=df)Code language: JavaScript (javascript)Furthermore, it’s also possible to change the markers of two, or more, categories. In the example below, we use a list with the cross and “star” and get a plot with crosses and stars, for each group.
sns.lmplot(x='wt', y='mpg',
hue='vs',
palette="Set1", markers=['+', '*'], data=df)Code language: JavaScript (javascript)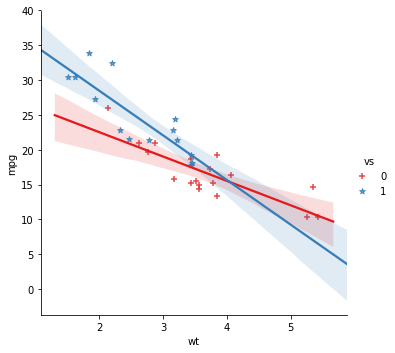
See here for different markers that can be used with Seaborn plots.
Seaborn Pairplot: Scatterplot + Histogram
In the last section, before learning how to save high-resolution images, we are going to use Seaborn’s pairplot method. The pairplot method will create pairs of plots
data = 'https://vincentarelbundock.github.io/Rdatasets/csv/datasets/mtcars.csv'
df = pd.read_csv(data, index_col=0)
# selecting specific columns:
df = df[['mpg', 'wt', 'hp', 'qsec']
# Creating the pairplot:
sns.pairplot(df)Code language: PHP (php)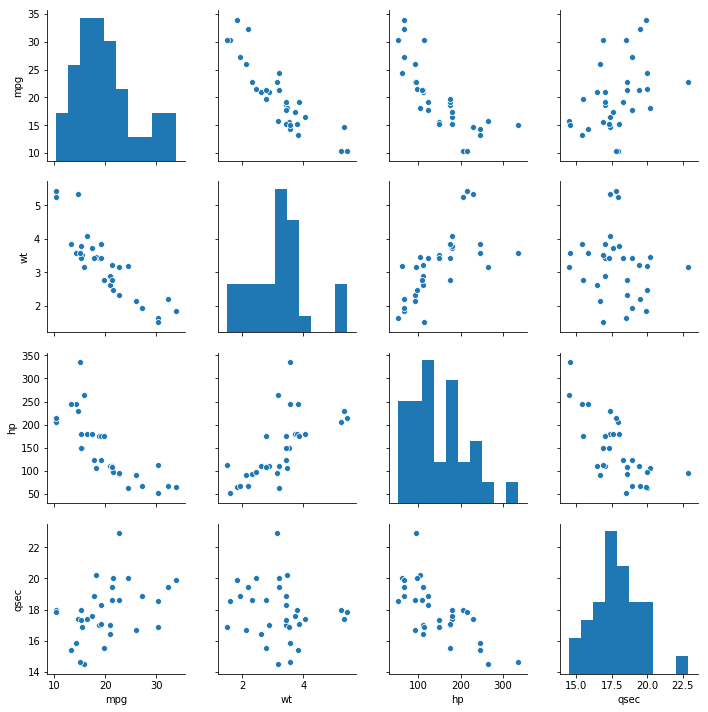
Now, pair plots are also possible to create with Pandas scatter_matrix method. Note, to change the name of the axis’ titles, we don’t really have to rename columns in the Pandas dataframe.
Pairplot with Grouped Data
If we want to group the data, with different colors for different categories, we can use the argument hue, also with pairplot. In this Python data visualization example we also use the argument vars with a list to select which variables we want to visualize:
cols = ['mpg', 'wt', 'hp', 'qsec']
sns.pairplot(df, vars=cols, hue='vs')Code language: Python (python)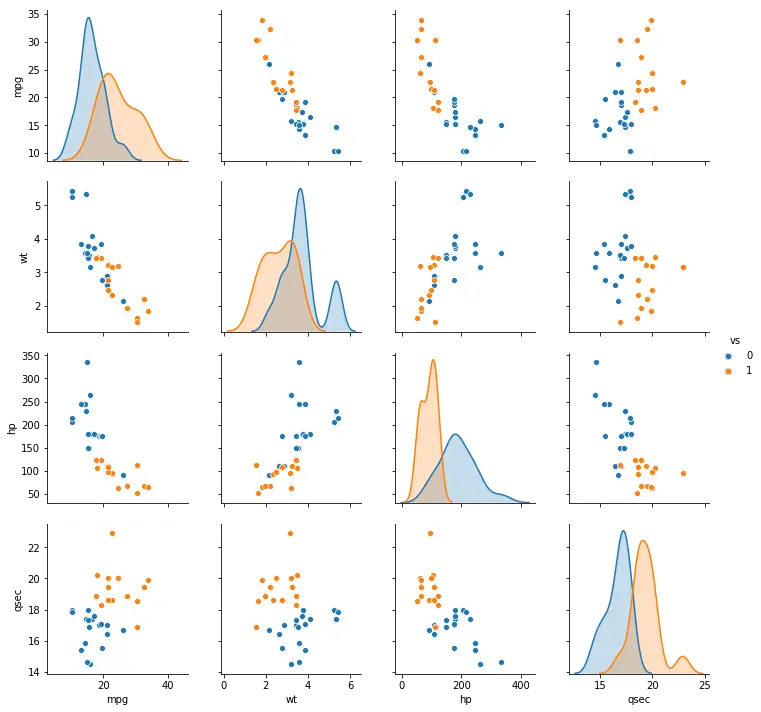
Saving a High-Resolution Plot in Python
If we are planning to publish anything we need to save the data visualization(s) to a high-resolution file. In the last code example, below, we will learn how to save a high-resolution image using Python and matplotlib.
Basically, there are three steps for creating and saving a Seaborn plot:
- Load the data using Pandas (e.g., using read_csv)
- Create the plot using Seaborn (e.g., using sns.pairplot)
- Use matplotlib (plt.savefig) to save the figure
Here’s an example of how to save a high-resolution figure:
ax = sns.pairplot(df, vars=cols, hue='vs')
plt.savefig('pairplot.eps', format='eps', dpi=300)Code language: Python (python)Here’s a link to a Jupyter Notebook containing all of the above code. More about saving Python plots can be found in the tutorial on how to save Seaborn plots as files. In this tutorial, we will go through how to save figures as PNG, EPS, TIFF, PDF, and SVG files.
Conclusion
In this post, we have learned how to make scatter plots in Seaborn. Moreover, we have also learned how to:
- work with the Seaborn’s scatterplot, regplot, lmplot, and pairplot methods
- change color, number of axis ticks, the markers, and how to rotate the axis labels of Seaborn plots
- save a high-resolution, and print-ready, image of a Seaborn plot
References
Here are some additional sources and references about Seaborn and/or scatter plots:
Oberoi, A., & Chauhan, R. (2019). Visualizing data using Matplotlib and Seaborn libraries in Python for data science. International Journal of Scientific and Research Publications, 9(3), 202–206. https://doi.org/10.29322/IJSRP.9.03.2019.p8733
Wang, Y., Han, F., Zhu, L., Deussen, O., & Chen, B. (2018). Line Graph or Scatter Plot? Automatic Selection of Methods for Visualizing Trends in Time Series. IEEE Transactions on Visualization and Computer Graphics, 24(2), 1141–1154. https://doi.org/10.1109/TVCG.2017.2653106
