In this Python data visualization tutorial, we will work with Pandas scatter_matrix method to explore trends in data. Previously, we have learned how to create scatter plots with Seaborn and histograms with Pandas. This post will focus on scatter matrices (pair plots) using Pandas.
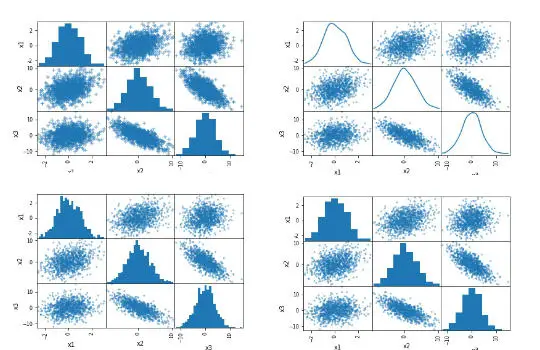
Table of Contents
- What is a Scatter Matrix?
- Prerequisites
- Pandas scatter_matrix Syntax
- Data Simulation using Numpy
- Pandas scatter_matrix (pair plot) Example 1:
- Pandas scatter_matrix (pair plot) Example 2:
- Pandas scatter_matrix (pair plot) Example 3:
- Pandas scatter_matrix (pair plot) Example 4:
- Scatter Matrix (pair plot) using other Python Packages
- Summary: 3 Simple Steps to Create a Scatter Matrix in Python with Pandas
- Resources
What is a Scatter Matrix?
A scatter matrix (pairs plot) compactly plots all the numeric variables we have in a dataset against each other. In Python, this data visualization technique can be carried out with many libraries, but if we are using Pandas to load the data, we can use the base scatter_matrix method to visualize the dataset.
Prerequisites
Now, this Python data visualization tutorial will require that we have Pandas and all its dependencies installed. It is very easy to install Pandas. We can use pip to install Python packages, such as Pandas, or we install a Python distribution (e.g., Anaconda, ActivePython). Here’s how to install Pandas with pip: pip install pandas.
Note, if a message that there is a newer version of pip available, check the post about how to upgrade pip.
Pandas scatter_matrix Syntax
In general, to create a scatter plot matrix with Pandas using the following syntax:
# Python scatter matrix with Pandas:
pandas.plotting.scatter_matrix(dataframe)Code language: Python (python)
Now, there are, of course, a number of parameters we can use (see image above for reference). In this Pandas scatter matrix tutorial, we are going to use hist_kwds, diagonal, and marker to create pair plots in Python. In the first example, however, we use the simple syntax of the scatter_matrix method (as above).
Data Simulation using Numpy
In this Pandas scatter matrix tutorial, we are going to create fake data to visualize. We will use NumPy to create three variables (x1, x2, and x3). Specifically, we use the normal method from NumPy random:
import numpy as np
import pandas as pd
np.random.seed(134)
N = 1000
x1 = np.random.normal(0, 1, N)
x2 = x1 + np.random.normal(0, 3, N)
x3 = 2 * x1 - x2 + np.random.normal(0, 2, N)Code language: Python (python)Next step, before visualizing the data, we create a Pandas dataframe from a dictionary.
df = pd.DataFrame({'x1':x1,
'x2':x2,
'x3':x3})
df.head()Code language: Python (python)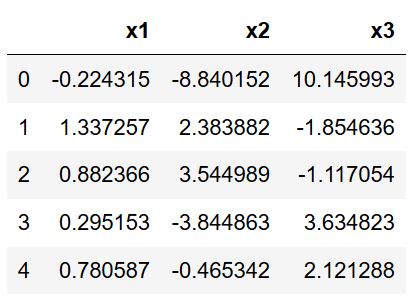
Now, you can see that we have variables x1, x2, and x3 as columns. Normally, we import data using Pandas read_csv or Pandas read_excel methods, for instance. Before moving on to the first example, it is worth mentioning that we can also convert a NumPy array to Pandas dataframe. Of course, we only need to do this if we have our data in, e.g., a 2-d NumPy array. Oh, when we are discussing this excellent Python package: make sure to check out how to convert a float array to an integer array (also with NumPy). Let us move on to the first example of creating a scatter matrix in Python!
Pandas scatter_matrix (pair plot) Example 1:
In the first example, we will only use the created dataframe as input. Here is the simplest way to create a scatter matrix in Python with Pandas:
# Creating the scatter matrix:
pd.plotting.scatter_matrix(df)Code language: Python (python)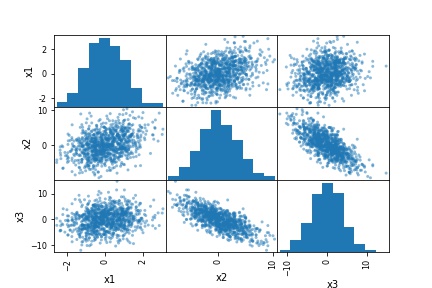
As evident in the scatter matrix above, we can produce a relatively complex matrix of scatterplots and histograms using only one single line of code. Now, what does this pair plot contain?
- The diagonal shows the distribution of the three numeric variables of our example data.
- In the other cells of the plot matrix, we have the scatterplots (i.e., correlation plots) of each variable combination of our dataframe. In the middle graphic in the first row, we can see the correlation between x1 & x2. Furthermore, in the right graph in the first row, we can see the correlation between x1 & x3; and finally, in the left cell in the second row, we can see the correlation between x1 & x2.
In this first example, we just went through the most basic usage of Pandas scatter_matrix method. It’s also possible to do a correlation matrix in Python to examine the correlation coefficients for the variables in a dataset. In the following examples, we are going to modify the pair plot (scatter matrix) a bit… First, we will change the number of bins in the histograms. In the third example, we will visualize a kde distribution instead of a histogram. Finally, we will also change the marker in the scatter plots.
Pandas scatter_matrix (pair plot) Example 2:
In the second example, on how to use Pandas scatter_matrix method to create a pair plot, we will use the hist_kwd parameter. Now, this parameter takes a Python dictionary as input. Here is how to create a scatter matrix with 30 bins:
# Changing the number of bins of the scatter matrix in Python:
pd.plotting.scatter_matrix(df, hist_kwds={'bins':30})Code language: Python (python)
Clearly, the scatter matrix that we now have produced is different from the one in the first example. We can see that there are more bins in the histograms. Refer to the documentation of Pandas hist method for more information about keywords that can be used or check the post about how to make a Pandas histogram in Python. Let’s move on to the next example!
Pandas scatter_matrix (pair plot) Example 3:
Now, in the third example, we are going to plot a density plot instead of a histogram. This is also very easy to accomplish. Here’s how to make visualize a scatter matrix with a density plot in Python:
# Scatter matrix with Pandas and density plots:
pd.plotting.scatter_matrix(df, diagonal='kde')Code language: Python (python)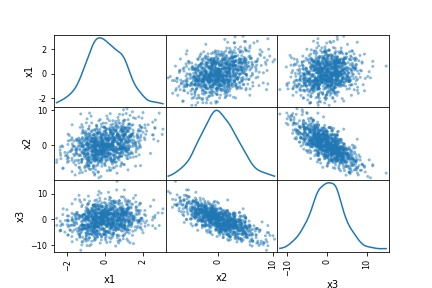
In the code chunk above, we added the diagonal parameter and added “kde”, which produced the beautiful visualization (also seen above). As evident, running that code produced a nice scatter matrix (pair plot) with density plots on the diagonal instead of a histogram. Note that the diagonal parameter takes either “hist” or “kde” as an argument. Thus, even if we wanted to have both density and histograms in our scatter matrix, we cannot.
Pandas scatter_matrix (pair plot) Example 4:
In the fourth example, we are going to change the marker. Here’s how to create a scatter matrix and changing the marker:
# Pandas scatter_matrix with "+" as markers
pd.plotting.scatter_matrix(df, marker='+')Code language: Python (python)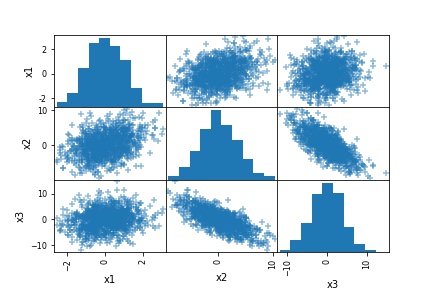
Scatter Matrix (pair plot) using other Python Packages
Now, there are some limitations to Pandas scatter_method. One limitation, for instance, is that we cannot plot both a histogram and the density of our data in the same plot. Another limitation is that we cannot group the data. Furthermore, we cannot plot the regression line in the scatter plot. However, if we use the Seaborn and the pairplot() method we can have more control over the scatter matrix. For instance, we can, using Seaborn pairplot() group the data, among other things. Another option is to use Plotly, to create the scatter matrix.
Summary: 3 Simple Steps to Create a Scatter Matrix in Python with Pandas
In this post, we have learned how to create a scatter matrix (pair plot) with Pandas. It was super simple, and here are three simple steps to use Pandas scatter_matrix method to create a pair plot:
Step 1: Load the Needed Libraries
In the first step, we will load pandas: import pandas as pd
Step 2: Import the Data to Visualize
In the second step, we will import data from a CSV file using Pandas read_csv method:
# Url to CSV file
csv_file = 'https://vincentarelbundock.github.io/Rdatasets/csv/MASS/survey.csv'
# Reading the CSV file from the URL
df_s = pd.read_csv(csv_file, index_col=0)
# Checking the data quickly (first 5 rows):
df_s.head()Code language: Python (python)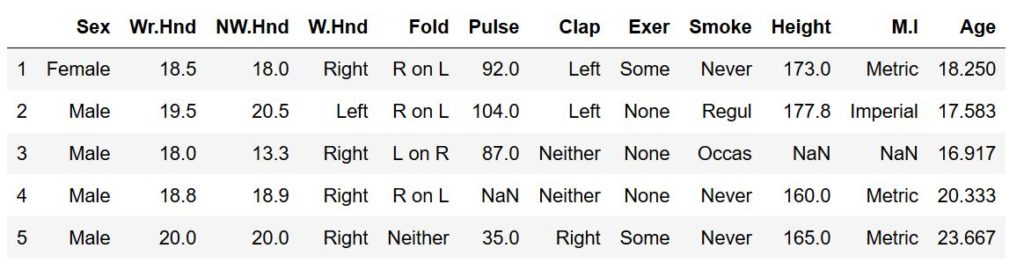
Step 3: Use Pandas scatter_matrix Method to Create the Pair Plot
In the final step, we create the pair plot using Pandas scatter_matrix method. Here’s the code needed to create the plot:
# Creating the scatter matrix
pd.plotting.scatter_matrix(df_s.iloc[:, 1:9])Code language: Python (python)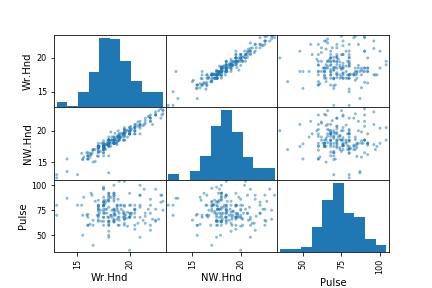
In the code chunk above, we use Pandas iloc to select certain columns. Note that in the pair plot above, Pandas scatter_matrix only chose the columns that have numerical values (from the ones we selected, of course). Here is a Jupyter Notebook with all the code in this blog post.
Resources
- Coefficient of Variation in Python with Pandas & NumPy
- Find the Highest Value in Dictionary in Python
- Python Scientific Notation & How to Suppress it in Pandas & NumPy
- Pandas Convert Column to datetime – object/string, integer, CSV & Excel
