In this post, we will work with Pandas iloc, and loc. More specifically, we are going to learn slicing and indexing by using these two methods..
Once a dataset is loaded as a Pandas dataframe, we often want to access specific parts of the data based on some criteria. For instance, if our dataset contains the result of an experiment comparing different experimental groups, we may want to calculate descriptive statistics for each experimental group separately.

The procedure of selecting specific rows and columns of data based on some criteria is commonly known as slicing.
Table of Contents
- Pandas Dataframes
- How to use Pandas iloc
- How to Use Pandas loc
- Pandas iloc and Conditions
- Setting Values in dataframes using .loc
- Conclusion
- Resources
Pandas Dataframes
Before we learn how to work with loc and iloc, we can be reminded of how the Pandas dataframe object works. For the specific purpose of this indexing and slicing tutorial, it is good to know that each row and column in the dataframe has a number – an index.
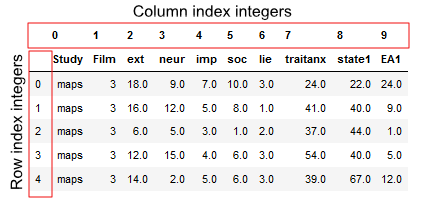
This row-and-column structure with numeric indexes, means that we can work with data by using the row and the column numbers. This is useful to know when we will work with Pandas’ loc and iloc methods.
- See also the blog post using Pandas and pyjanitor, to learn about some easy Python data cleansing methods.
Data
In the following iloc and loc examples, we will work with two datasets. These datasets, among a lot of other RDatasets, can be found here, but the following code will load them into Pandas dataframes:
import pandas as pd
url_dataset1 = 'https://vincentarelbundock.github.io/Rdatasets/csv/psych/affect.csv'
url_dataset2 = 'https://vincentarelbundock.github.io/Rdatasets/csv/DAAG/nasshead.csv'
df1 = pd.read_csv(url_dataset1, index_col=0)
df2 = pd.read_csv(url_dataset2, index_col=0)Code language: Python (python)If you are interested in learning more about in-and-out methods of Pandas make sure to check the following posts out:
- How to read CSV files in Pandas
- How to read Excel files in Pandas
- Reading SPSS files in Pandas
- Working with JSON files using Python and Pandas
Before working with Pandas iloc and Pandas loc, we will answer the question concerning the difference between them.
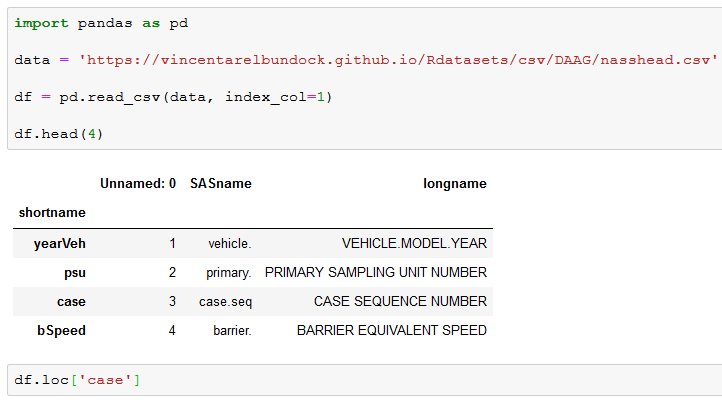
First, .loc is a label-based method, whereas .iloc is an integer-based method. This means that iloc will consider the names or labels of the index when we are slicing the dataframe.
For example, if “case” is in the index of a dataframe (e.g., df), df.loc[‘case’] it will result in the third row being selected. Note, in the loc and iloc examples below, we will work with the first column, in the dataset, as index (see first code chunk).
On the other hand, Pandas .iloc takes slices based on index’s position. Unlike .loc, .iloc behaves like regular Python slicing. That is, we indicate the positional index number, and we get the slice we want.
For example, df.iloc[2] will give us the third row of the dataframe. This is because, like in Python, .iloc is zero positional based. That is it starts at 0. We will learn how we use loc and iloc, in the following sections of this post.
As previously mentioned, Pandas iloc is primarily integer position based. It can index a dataframe using 0 to length-1, whether it’s the row or column indices.
Furthermore, as we will see in a later Pandas iloc example, the method can also be used with a boolean array.
The image below provides a quick example of how to work with Pandas’ df.loc[] method.
Here is a short YouTube video in which you can learn how to work with both loc and iloc:
In this Pandas iloc tutorial, we are going to work with the following input methods:
- An integer, e.g. 2
- A list of integers, e.g. [7, 2, 0]
- A slice object with ints, e.g. 0:7, as in the image above
- A boolean array.
How to use Pandas iloc
Now, you may be wondering, “How do I use iloc?” Of course, we are going to answer that question. In the simplest form, we just type an integer between the brackets.
df1.iloc[0]Code language: Python (python)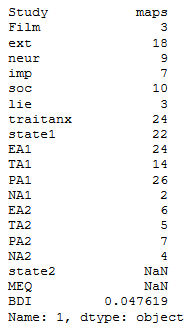
As seen in the Pandas iloc example, above, we typed a set of brackets after the iloc method.
Furthermore, we added an integer (0) as index value to specify that we wanted the first row of our dataframe. Note, when working with .iloc it is important to know that the order of the indexes inside the brackets matters.
The first index number will be the row or rows we want to retrieve. If we want to retrieve a specific column, we input a second index (or indices) using iloc. This, however, is optional, and without a second index, iloc will retrieve all columns by default.
Pandas iloc syntax is, as previously described, DataFrame.iloc[<row selection>, <column selection>].

This may be confusing for users of the R statistical programming environment. To iterate, the iloc method in Pandas is used to select rows and columns by number, in the order that they appear in the dataframe.
Pandas iloc Examples
In the next section, we continue this Pandas indexing and slicing tutorial by looking at different examples of using iloc. We have, of course, already started with the most basic one, selecting a single row:
df1.iloc[3]Code language: Python (python)Indexing the last Row of a Pandas dataframe
In the following example, we are continuing using one integer to index the dataframe. However, if we want to retrieve the last row of a Pandas dataframe we use “-1”:
df1.iloc[-1]Code language: Python (python)We can also input a list with only one index integer when we use iloc. This will index one row, but the output will be different compared to the example above:
df1.iloc[[-1]]Code language: Python (python)
Select Multiple Rows using iloc
We can, of course, also use iloc to select many rows from a pandas dataframe. For instance, if we add more index integers to the list, like in the example above, we can choose many rows.
df.iloc[[7, 2, 0]]Code language: Python (python)
Slicing Rows using iloc in Pandas
In the following Pandas iloc example, we will learn about slicing. Note that we are going to get more familiar with using the slicing character “:” later in this post. To select row 11 to 15 we type the following code:
df1.iloc[10:15]Code language: Python (python)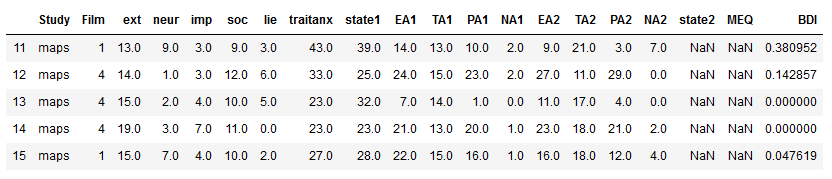
Selecting Columns with Pandas iloc
As previously indicated, we can, of course, when using the second argument in the iloc method also select, or slice, columns. In the following iloc example, we want to retrieve only the first column of the dataframe, which is the column at index position 0.
To do this, we will use an integer index value in the second position inside the brackets when using iloc. Note that the second position’s integer index specifies the column we want to retrieve. What about the rows?
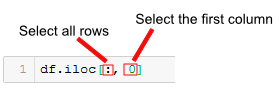
Note that when we want to select all rows and one column (or many columns) using iloc, we need to use the “:” character.
# Select Columns with Pandas iloc
df1.iloc[:, 0]Code language: Python (python)
In the Pandas iloc example above, we used the “:” character in the first position inside the brackets. This indicates that we want to retrieve all the rows. A reminder: the first index position inside of [] specifies the rows, and we used the “:” character to get all rows from a Pandas dataframe.
In the following example of how to use Pandas iloc, we will take a slice of the columns and all rows. This can be done in a similar way to the one above. However, instead of using an integer we use a Python slice to get all rows and the first 6 columns:
df1.iloc[:, 0:6]Code language: Python (python)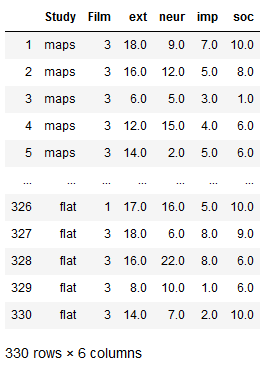
Select a Specific Cell using iloc
In this section, of the Pandas iloc tutorial, we will learn how to select a specific cell.
This is quite simple, of course, and we just use an integer index value for the row and the column we want to get from the dataframe. For example, if we want to select the data in row 0 and column 0, we just type df1.iloc[0, 0].
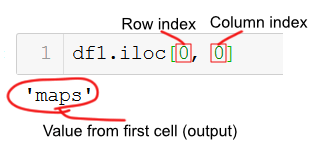
Of course, we can also select multiple rows and/or multiple columns. To do this we just add a list with the integer indices that we want iloc to select for us.
For example, if we want to select the data in row 4 and column 2, 3, and 4 we just use the following code:
df1.iloc[3, [1, 2, 3]]Code language: Python (python)Retrieving subsets of cells
In the next iloc example, we will get a subset of cells from the dataframe.
Achieving this is a combination of getting a slice of columns and a slice of rows with iloc:
df1.iloc[0:5, 3:7]Code language: Python (python)Selecting Columns using a Boolean Mask
In the final example, we will select columns using a boolean mask. Of course, this requires us to know how many columns there are and which columns we want to select.
bool_i = [False, False, True, True, True,
True, True, True, True, True,
True, True, True, True, True,
True, True, True, False, False]
df.iloc[3:7, bool_i]Code language: Python (python)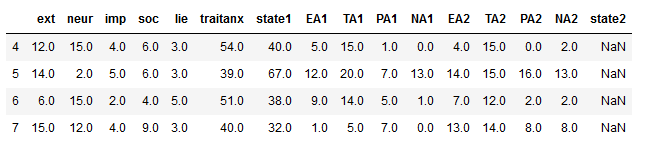
How to Use Pandas loc
In this section, we cover another Pandas method, i.e. loc for selecting data from dataframes.
When to use loc?
Remember, whereas iloc takes positional references as the argument input, loc takes indexes. As loc takes indexes, we can pass strings (e.g., column names) as an argument, whereas it will throw an error if we use strings with iloc. So, the answer to the question of when to use Pandas loc? is when we know the index names.
In this loc tutorial, we are going to use the following inputs:
- A single label, for instance 2 or ‘b’.
It is worth noting here that Pandas interpret 2 as a label of the index and not as an integer position along the index (contrary to iloc) - A list of labels, for instance [‘a’, ‘b’, c’]
- A slice object with labels, for example,. ‘shortname’:’SASname’. Importantly, when it comes to slices when we use loc, BOTH the start and stop are included
Select a Row using Pandas loc
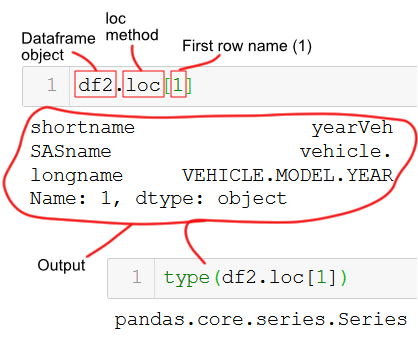
In the first Pandas loc example, we will select data from the row where the index is equal to 1.
df2.loc[1]Code language: Python (python)Note, in the example above the first row has the name “1”. That is, this is not the index integer but the name.
Pandas loc behaves in the same manner as iloc, and we retrieve a single row as a series. Just as with Pandas iloc, we can change the output to get a single row as a dataframe. We do this by putting the row name in a list:
df2.loc[[1]]Code language: Python (python)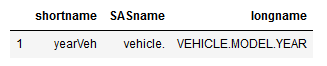
Slicing Rows using loc
In the following code example, we will take a slice of rows using the row names.
df2.loc[1:5]Code language: Python (python)
We can also pass it a list of indexes to select required indexes.
df2.loc[[1, 6, 11, 21, 51]]Code language: Python (python)
Selecting by Column Names using loc
Unlike Pandas iloc, loc further takes column names as column argument. This means we can pass it a column name to select data from that column.
In the next loc example, we will select all the data from the ‘SASname’ column.
df2.loc[:, 'SASname']Code language: Python (python)Another option is, of course, to pass multiple column names in a list when using loc. In the next example, we are selecting data from the ‘SASname’ and ‘long name’ columns, where the row names range from 1 to 5.
df2.loc[1:5, ['SASname', 'longname']]Code language: Python (python)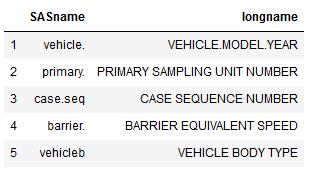
Slicing using loc in Pandas
In this section, we will see how to slice a Pandas dataframe using loc. Remember that the “:” character is used when slicing. As with iloc, we can also slice, but here we can include column names and row names (like in the example below).
In the loc example below, we use the first dataframe again (df1, that is) and slice the first 5 rows and take the columns from the ‘Film’ column to the ‘EA1’ column.
df1.loc[1:5, 'Film':'EA1']Code language: Python (python)Pandas iloc and Conditions
Many times, we want to index a Pandas dataframe using boolean arrays. That is, we may want to select data based on certain conditions. This is relatively easy to do with Pandas loc, of course. We just pass an array or Seris of True/False values to the .loc method.
Selecting Rows based on a Condition with Pandas loc
For example, if we want to select all rows where the value in the Study column is “flat,” we do the following: create a Pandas Series with a True value for every row in the dataframe where “flat” exists.
df1.loc[df1['Study'] == 'flat']Code language: Python (python)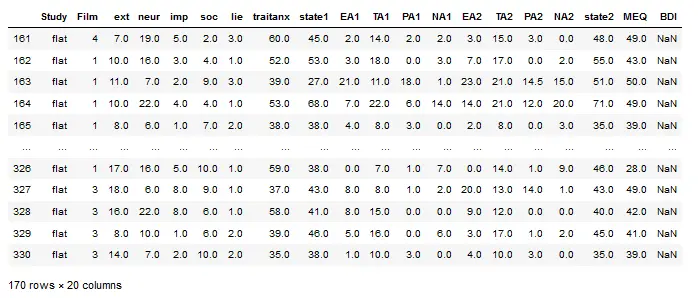
Select Rows using Multiple Conditions Pandas iloc
Furthermore, we may sometimes want to select based on multiple conditions. For instance, if we want to select all rows where the value in the Study column is “flat” and the value in the neur column is more larger than 18 we do as in the following example:
df1.loc[(df1['neur'] > 18) & (df1['Study'] == 'flat')]Code language: Python (python)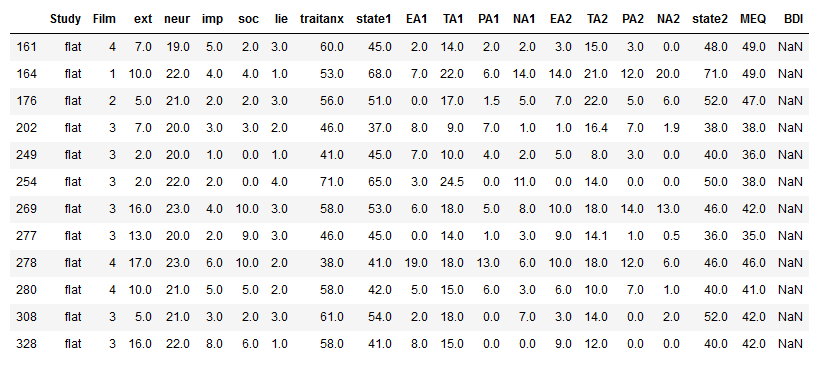
As before, we can use a second to select particular columns from the dataframe. Remember, when working with Pandas loc, columns are referred to by name for the loc indexer and we can use a single string, a list of columns, or a slice “:” operation. In the following example, we select the columns from EA1 to NA2:
df1.loc[(df1['neur'] > 18) & (df1['Study'] == 'flat'), 'EA1':'NA2']Code language: Python (python)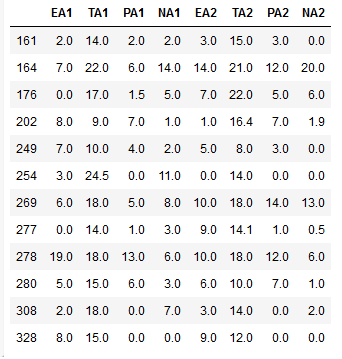
Setting Values in dataframes using .loc
In the last section of this loc and iloc tutorial, we will learn how to set values to the dataframe using loc.
Setting values to a dataframe is easy all we need is to change the syntax a bit, and we can update the data in the same statement as we select and filter using .loc indexer. This is handy as we can to update values in columns depending on different conditions.
In the final loc example, we are going to create a new column (NewCol) and add the word “BIG” there in the rows where neur is larger than 18:
df1.loc[df1['neur'] > 18, 'NewCol'] = 'BIG'
df1.loc[df1['neur'] > 18, 'EA1':'NewCol'].head()Code language: JavaScript (javascript)Conclusion
In this Pandas iloc and loc tutorial, we have learned indexing, selecting, and subsetting using the loc and iloc methods. More specifically, we have learned how these methods work. When it comes to loc, we have learned how to select based on conditional statements (e.g., larger than or equal to) and how to set values using loc.
Resources
- Adding New Columns to a Dataframe in Pandas (with Examples)
- How to Plot a Histogram with Pandas in 3 Simple Steps
- Python Scientific Notation & How to Suppress it in Pandas & NumPy
- How to Filter in data.table in R

The first look up code fails for me in Python 3.7.3 and Pandas 0.24.2:
df2.loc[‘ case ‘]
You set the index_col to 0 for df2, that is not the column that contains ‘case’, but is a column of integers. Column 1 of the nasshead.csv contains the index value that works in your example.
Also, when you put that code: df2.loc[‘ case ‘] in your HTML text, the quotes are published incorrectly for coding.
I stopped your tutorial there, but a few lines further on you refer to:
df.iloc[0]
I do not see that you create a dataframe named ‘df’
Hey Dave,
Thanks for your comment. That line of code was thought to be an example and not something to be followed in the code. However, as to minimize confusion I have updated the post to clarify this. I also added an image showing how you could replicate that particular example also. In the examples, later in the loc and iloc tutorial, it’s df1 and df2 that is used. As the names of the indexes, in the dataframes, are numbers
df2.loc[3]would give you the third row.Again, thanks for your comment.
great tutorial, thank you a lot
You explain this very nice and clear. One of the best. Thanks.
Thanks William! Glad you liked it!