In this post, we are going to learn how to do simplify our data preprocessing (e.g, data cleaning) using the Python package Pyjanitor. More specifically, we are going to learn how to:
- Add a column to a Pandas dataframe
- Remove missing values
- Remove an empty column
- Cleaning up column names
Table of Contents
- Clean Data in Python
- Fake Data to Clean using Python
- Data Cleaning in Python with Pandas and Pyjanitor
- How to Clean Data when Loading the Data from Disk
- Aggregating Data using Pyjanitor
- Conclusion:
- Resources
Clean Data in Python
That is, we will learn how to clean Pandas dataframes using Pyjanitor. In all Python data manipulation examples, here we are also going to see how to carry out them using only Pandas functionality.
What is Pyjanitor? Before we continue learning how to use Pandas and Pyjanitor to clean our datasets, we will learn about this package. The Python package Pyjanitor extends Pandas with a verb-based API. This easy-to-use API provides us with convenient data-cleaning techniques. It started as a port of the R package janitor. Furthermore, it is inspired by the ease of use and expressiveness of the r-package dplyr. Note, there are different ways to work with the methods, and this post will not cover all of them (see the documentation).
How to install Pyjanitor
There are two easy methods to install Pyjanitor:
1. Installing Pyjanitor using Pip
pip install pyjanitorCode language: Bash (bash)2. Installing Pyjanitor using Conda:
conda -c install conda-forge pyjanitorCode language: Bash (bash)Now that we know what Pyjanitor is and how to install the package we soon can continue the Python data cleaning tutorial by learning how to remove missing values from Pandas. Note, that this Pandas tutorial will walk through each step on how to do it using Pandas and Pyjanitor. Ultimately, we will have a complete data cleaning example using only Pyjanitor and a link to a Jupyter Notebook with all code. Now, it is quite easy to install Python packages but sometimes we may get a message that we need to update pip (make sure to check that post out).
Fake Data to Clean using Python
In the first Python data manipulation examples, we are going to work with a fake dataset. More specifically, we are going to create a dataframe, with an empty column, and missing values. In this part of the post we are, further, going to use the Python packages SciPy, and NumPy. That is, these packages also need to be installed.
In this example, we are going to create three columns; Subject, RT (response time), and Deg. To create the response time column, we will use SciPy norm to create data that is normally distributed.
import numpy as np
import pandas as pd
from scipy.stats import norm
from random import shuffle
import janitor
subject = ['n0' + str(i) for i in range(1, 201)]Code language: Python (python)Python Normal Distribution using Scipy
In the next code chunk, we create a variable, for response time, using a normal distribution.
a = 457
rt = norm.rvs(a, size=200)Code language: Python (python)Shuffling the List and Adding Missing Values
Furthermore, we are adding some missing values and shuffling the list of normally distributed data:
# Shuffle the response times
shuffle(rt)
rt[4], rt[9], rt[100] = np.nan, np.nan, np.nanCode language: PHP (php)
Data Cleaning in Python with Pandas and Pyjanitor
In this section, we will start by learning how to add a column to Pandas dataframe.
How to Add a Column to Pandas Dataframe
Now that we have created our dataframe from a dictionary, we are ready to add a column to it. In the examples, below, we are going to use Pandas and Pyjanitors method.
1. Append a Column to Pandas Dataframe
It’s quite easy to add a column to a dataframe using Pandas. In the example below, we will append an empty column to the Pandas dataframe:
data = {
'Subject': subject,
'RT': rt,
}
df = pd.DataFrame(data)
df.head()Code language: Python (python)
In the example above, we did add empty columns to a dataframe in Pandas. Note, however, that there are plenty of other methods to insert columns, whether with values or empty, into a dataframe.
How to Remove Missing Values in Pandas Dataframe
It is quite common that our dataset is far from complete. This may be due to errors in the measurement instruments, people forgetting, or refusing, to answer certain questions, amongst many other things. Despite the reason behind missing information, these rows are called missing values. In the framework of Pandas the missing values are coded by the symbol NA, much like in R statistical environment. Pandas have the function isna() to help us identify missings in our dataset. If we want to drop missing values, Pandas have the function dropna().
1 Dropping Missing Values using Pandas dropna method
In the code example below we are dropping all rows with missing values. Note, if we want to modify the dataframe we should add the inplace parameter and set it to true.
df['NewColumnName'] = np.nan
df.head()Code language: Python (python)
Dropping Missing Values from Pandas Dataframe using PyJanitor
The method to drop missing values from a Pandas Dataframe using Pyjanitor is the same as the one above. That is, we are going to use the dropna method. However, when using Pyjanitor we also use the parameter subset to select which column(s) we are going to use when removing missing data from the dataframe:
newcolvals = [np.nan]*len(df['Subject'])
df = df.add_column('NewColumnName2', newcolvals)
df.head()Code language: Python (python)How to Remove an Empty Column from Pandas Dataframe
In the next Pandas data manipulation example, we are going to remove the empty column from the dataframe. First, we are going to use Pandas to remove the empty column and, then, we are going to use Pyjanitor. Remember, towards the end of the post we will have a complete example in which we carry out all data cleaning while actually creating the Pandas Dataframe.
1. Removing an Empty Column from Pandas Dataframe
When we want to remove an empty column (e.g., with missing values) we use the Pandas method dropna again. However, we use the axis method and set it to 1 (for column). Furthermore, we also have to use the parameter how and set it to ‘all’. If we don’t it will remove any column with missing values
2. Deleting an Empty Column from Pandas Dataframe using Pyjanitor
It’s a bit easier to remove an empty column using Pyjanitor:
df.remove_empty()Code language: Python (python)How to Rename Columns in Pandas Dataframe
Now that we know how to remove missing values, add a column to a Pandas dataframe, and how to remove a column, we are going to continue this data cleaning tutorial learning how to rename columns.
For instance, in the post where we learned how to load data from a JSON file to a Pandas dataframe, we renamed columns to make it easier to work with the dataframe later. In the example below, we will read a JSON file, and rename columns using both Pandas dataframe method rename and Pyjanitor.
import requests
from pandas.io.json import json_normalize
url = "https://datahub.io/core/s-and-p-500-companies-financials/r/constituents-financials.json"
resp = requests.get(url=url)
df = json_normalize(resp.json())
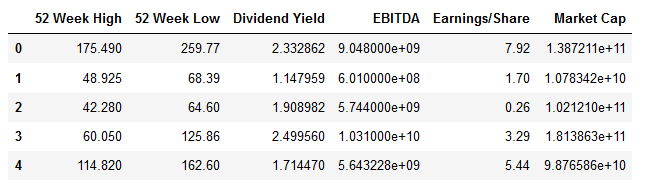
df.iloc[:,0:6].head()Code language: Python (python)- Learn more about how to use iloc to slice Pandas dataframes by rows and columns
More about loading data to dataframes:
- How to Read and Write JSON Files using Python and Pandas
- Pandas Read CSV Tutorial
- Pandas Excel Tutorial: How to Read and Write Excel files
1 Renaming Columns in Pandas Dataframe
As can be seen in the image above, there are some whitespaces and special characters that we want to remove. In the first renaming columns example, we are going to use Pandas rename method together with regular expressions to rename the columns (i.e., we are going to replace whitespaces and \ with underscores).
import re
df.rename(columns=lambda x: re.sub('(\s|/)','_',x),
inplace=True)
df.keys()Code language: Python (python)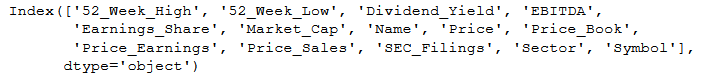
In the code above, we use the keys() to print the variables names. Another option is to use df.columns to get a list of the column names in the dataframe.
2. How to Rename Columns using Pyjanitor and clean_names
The task to rename a column (or many columns) is way easier using Pyjanitor. In fact, when we have imported this Python package, we can just use the clean_names method and it will give us the same result as using Pandas rename method. Moreover, using clean_names we also get all letters in the column names to lowercase:
df = df.clean_names().head()
df.keys()Code language: Python (python)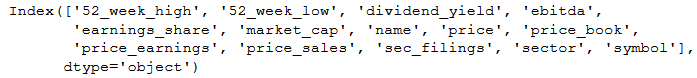
In a more recent post, more information about renaming columns in Pandas dataframe can be found.
How to Clean Data when Loading the Data from Disk
The cool thing with using Pyjanitor to clean our data is that we can do use all of the above methods when loading our data. For instance, in the final data cleaning example, we are going to add a column to the dataframe, remove empty columns, drop missing data, and clean the column names. This is what makes working with Pyjanitor our lives easier because we can carry out data cleaning directly when reading the data.
data_id = [1]*200
url = 'https://raw.githubusercontent.com/marsja/jupyter/master/SimData/DF_NA_Janitor.csv'
df = (
pd.read_csv(url,
index_col=0)
.add_column('data_id', data_id)
.remove_empty()
.dropna()
.clean_names()
)
df.head()Code language: Python (python)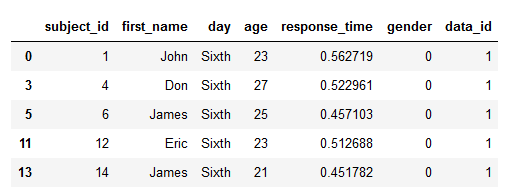
Aggregating Data using Pyjanitor
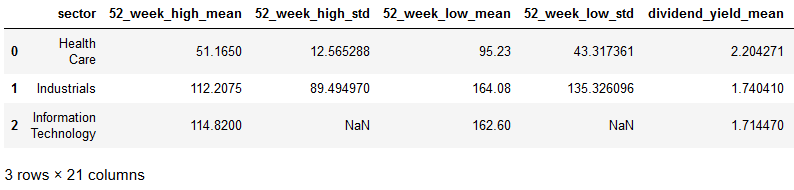
In the last example, we are going to use Pandas methods agg, groupby, and reset_index together with the Pyjanitor method collapse_levels to calculate the mean and standard for each sector:
df.groupby('sector').agg(['mean',
'std']).collapse_levels().reset_index()Code language: Python (python)Now, if you ever want to make a column index in Pandas dataframe, you could also use the set_index() method.
More about grouping and aggregating data using Python and Pandas:
Conclusion:
In this post, we have learned how to do some data cleaning methods. Specifically, we have learned how to append a column to a Pandas dataframe, remove empty columns, handling missing values, and renaming the columns (i.e., getting better column names). There are, of course, many more data cleaning methods available, both when it comes to Pandas and Pyjanitor.
In conclusion, the methods added by the Python package are both similar to the one of the R-package janitor and dplyr. These methods will make our lives easier when preprocessing our data.
What is your favorite data cleaning method and/or Package? It can be either using R, Python, or any other programming language. Leave a comment below!
Resources
- How to Convert a Python Dictionary to a Pandas DataFrame
- How to Get the Column Names from a Pandas Dataframe – Print and List
