In this post, we will learn how to use Pandas get_dummies() method to create dummy variables in Python. Dummy variables (or binary/indicator variables) are often used in statistical analyses and in more simple descriptive statistics. Towards the end of the post, you will find a link to a Jupyter Notebook containing all Pandas get_dummies() examples.
How to Create Dummy Variables in Python
To create dummy variables in Python with Pandas, we can use this code template:
# Creating dummy variables:
df_dc = pd.get_dummies(df, columns=['ColumnToDummyCode'])Code language: Python (python)In the code chunk above, df is the Pandas dataframe, and we use the columns argument to specify which columns we want to be dummy code (see the following examples, in this post, for more details).
Read more: How to use Pandas get_dummies to Create Dummy Variables in PythonTable of Contents
- How to Create Dummy Variables in Python
- Dummy Coding for Regression Analysis
- Installing Pandas
- Example Data to Dummy Code
- Creating Dummy Variables in Python
- Conclusion: Dummy Coding in Python
- Additional Resources
- Python Tutorials:
Dummy Coding for Regression Analysis
One statistical analysis in which we may need to create dummy variables in regression analysis. In fact, regression analysis requires numerical variables and this means that when we, whether doing research or just analyzing data, wishes to include a categorical variable in a regression model, supplementary steps are required to make the results interpretable.
In these steps, categorical variables in the data set are recoded into a set of separate binary variables (dummy variables). Furthermore, this re-coding is called “dummy coding” and involves the creation of a table called contrast matrix. Statistical software, such as R, SPSS, or Python, can automatically do dummy coding.
In this section of the creating dummy variables in Python guide, we will answer the question about what categorical data is. Now, in statistics, a categorical variable (also known as factor or qualitative variable) is a variable that takes on one of a limited, and most commonly a fixed number of possible values. Furthermore, these variables typically assign each individual or another observation unit to a particular group or nominal category. For example, gender is a categorical variable.
Now, the next question we will answer before working with Pandas get_dummies, is, “what is a dummy variable?”. Typically, a dummy variable (or column) has a value of one (1) when a categorical event occurs (e.g., an individual is male) and zero (0) when it doesn’t occur (e.g., an individual is female).
To convert your categorical variables to dummy variables in Python, you can use Pandas get_dummies() method. For example, if you have the categorical variable “Gender” in your dataframe called “df” you can use the following code to make dummy variables:df_dc = pd.get_dummies(df, columns=['Gender']). If you have multiple categorical variables you add every variable name as a string to the list!
Installing Pandas
Obviously, we need to have Pandas installed to use the get_dummies() method. Pandas can be installed using pip or conda, for instance. If we want to install Pandas using condas we type conda install pandas. On the other hand, if we want to use pip, we type pip install pandas. Note, it is typically suggested that Python packages are installed in virtual environments. Pipx can be used to install Python packages directly in virtual environments and if we want to install, update, and use Python packages we can, as in this post, use conda or pip.
Finally, if there is a message that there is a newer version of pip, make sure to check out the post about how to up update pip.
Example Data to Dummy Code
In this Pandas get_dummies tutorial, we will use the Salaries dataset, which contains the 2008-09 nine-month academic salary for Assistant Professors, Associate Professors, and Professors in a college in the U.S.
Import Data in Python using Pandas
Now, before we start using Pandas get_dummies() method, we need to load pandas and import the data.
import pandas as pd
data_url = 'http://vincentarelbundock.github.io/Rdatasets/csv/carData/Salaries.csv'
df = pd.read_csv(data_url, index_col=0)
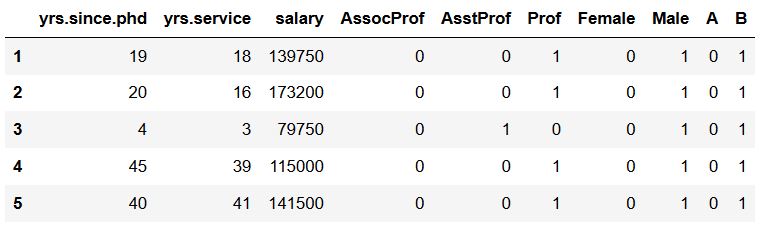
df.head()Code language: Python (python)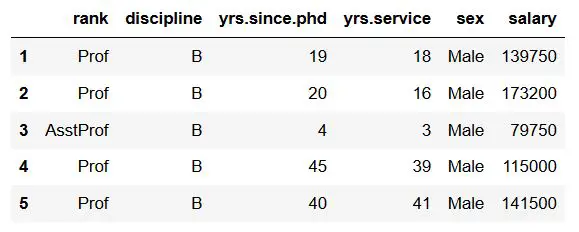
Of course, data can be stored in multiple different file types. For instance, we could have our data stored in .xlsx, SPSS, SAS, or STATA files. See the following tutorials to learn more about importing data from different file types:
- Learn how to read Excel (.xlsx) files using Python and Pandas
- Read SPSS files using Pandas in Python
- Import (Read) SAS files using Pandas
- Read STATA files in Python with Pandas
Now, if we only want to work with Excel files, reading xlsx files in Python, can be done with other libraries, as well.
Creating Dummy Variables in Python
In this section, we are going to use pandas get_dummies() to generate dummy variables in Python. First, we are going to work with the categorical variable “sex”. That is, we will start with dummy coding a categorical variable with two levels.
Second, we are going to generate dummy variables in Python with the variable “rank”. That is, in that dummy coding example we are going to work with a factor variable with three levels.
How to Make Dummy Variables in Python with Two Levels
In this section, we are going to create a dummy variable in Python using Pandas get_dummies method. Specifically, we will generate dummy variables for a categorical variable with two levels (i.e., male and female).

In this create dummy variables in Python post, we are going to work with Pandas get_dummies(). As can be seen, in the image above we can change the prefix of our dummy variables, and specify which columns that contain our categorical variables.
First Dummy Coding in Python Example:
In the first Python dummy coding example below, we are using Pandas get_dummies to make dummy variables. Note, we are using a series as data and, thus, get two new columns named Female and Male.
# Pandas get_dummies on one column:
pd.get_dummies(df['sex']).head()Code language: Python (python)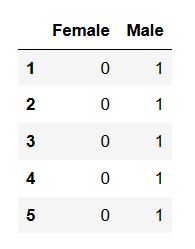
In the code, above, we also printed the first 5 rows (using Pandas head()). We will now continue and use the columns argument. Here we input a list with the column(s) we want to create dummy variables from. Furthermore, we will create the new Pandas dataframe containing our new two columns.
How to Create Dummy variables in Python Video Tutorial
For those that prefer, here’s a video describing most of what is covered in this tutorial.
More Python Dummy Coding Examples:
# Creating dummy variables from one column:
df_dummies = pd.get_dummies(df, columns=['sex'])
df_dummies.head()Code language: Python (python)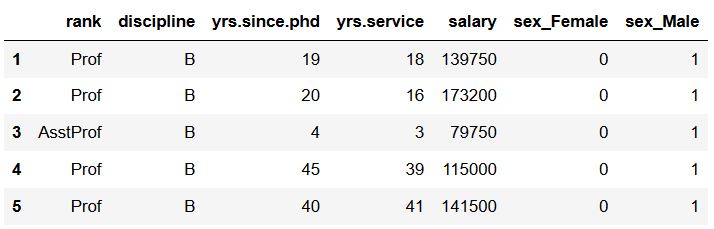
In the output (using Pandas head()), we can see that Pandas get_dummies automatically added “sex” as prefix and underscore as prefix separator. If we, however, want to change the prefix as well as the prefix separator we can add these arguments to Pandas get_dummies():
# Changing the prefix for the dummy variables:
df_dummies = pd.get_dummies(df, prefix='Gender', prefix_sep='.',
columns=['sex'])
df_dummies.head()Code language: Python (python)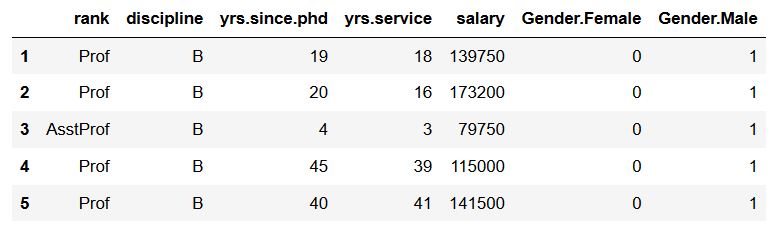
Remove Prefix and Separator from Dummy Columns
In the next Pandas dummies example code, we are going to make dummy variables with Python but we will set the prefix and the prefix_sep arguments so that we the column name will be the factor levels (categories):
# Remove the prefix and separator when dummy coding:
df_dummies = pd.get_dummies(df, prefix=, prefix_sep='',
columns=['sex'])
df_dummies.head()Code language: Python (python)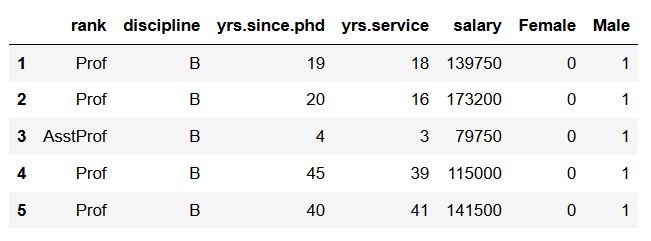
How to Create Dummy Variables in Python with Three Levels
In this section of the dummy coding in Python tutorial, we are going to work with the variable “rank”. That is, we will create dummy variables in Python from a categorical variable with three levels (or 3 factor levels). In the first dummy variable example below, we are working with Pandas get_dummies() the same way as we did in the first example.
# Python dummy variables with 3 factor levels (categorical data):
pd.get_dummies(df['rank']).head()Code language: Python (python)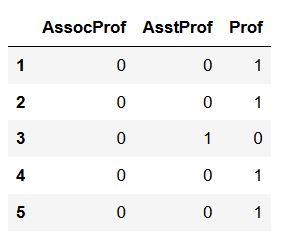
That is, we put in a Pandas Series (i.e., the column with the variable) as the only argument and then we only got a new dataframe with 3 columns (i.e., for the 3 levels).
Create a Dataframe with Dummy Coded Variables
Of course, we want to have the dummy variables in a dataframe with the data. Again, we do this by using the columns argument and a list with the column that we want to use:
df_dummies = pd.get_dummies(df, columns=['rank'])
df_dummies.head()Code language: Python (python)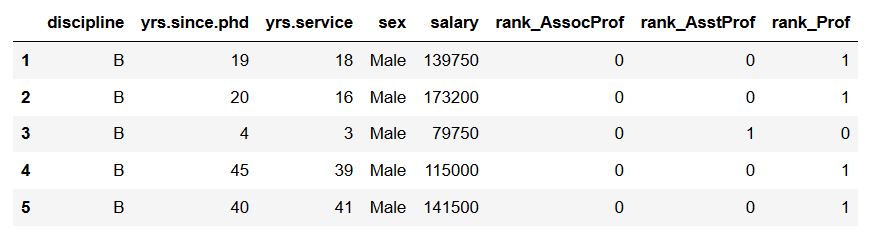
In the image above, we can see that Pandas get_dummies() added “rank” as prefix and underscore as prefix separator. Next, we are going to change the prefix and the separator to “Rank” (uppercase) and “.” (dot).
df_dummies = pd.get_dummies(df, prefix='Rank', prefix_sep='.',
columns=['rank'])
df_dummies.head()Code language: Python (python)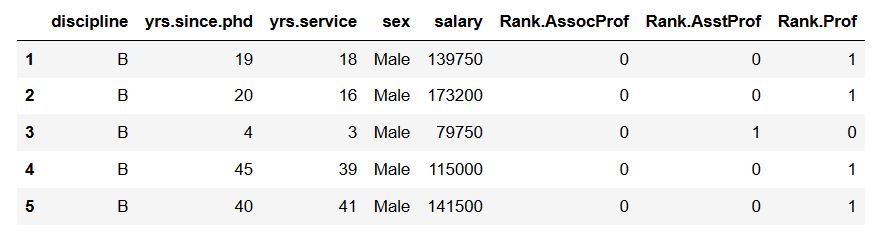
Now, we may not need to have a prefix or a separator and, as in the previous Pandas create dummy variables in Python example, want to remove these. To accomplish this, we add empty strings to the prefix and prefix_sep arguments:
df_dummies = pd.get_dummies(df, prefix='', prefix_sep='',
columns=['rank'])Code language: Python (python)Creating Dummy Variables in Python for Many Columns/Categorical Variables
In the final Pandas dummies example, we are going to dummy code two columns. Specifically, we are going to add a list with two categorical variables and get 5 new columns that are dummy coded. This is, in fact, very easy and we can follow the example code from above:
Creating Multiple Dummy Variables Example Code:
Here’s how to create dummy variables from multiple categorical variables in Python:
# Making dummy variables of two columns:
df_dummies = pd.get_dummies(df, prefix='', prefix_sep='',
columns=['rank', 'sex'])
df_dummies.head()Code language: Python (python)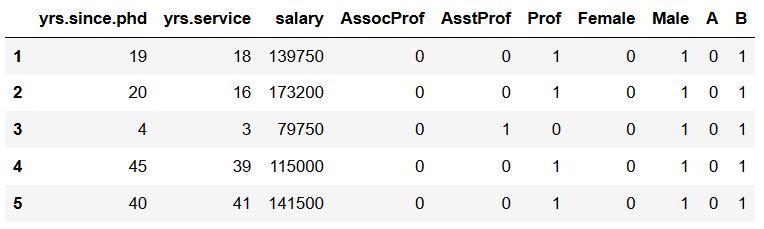
Finally, if we want to add more columns, to create dummy variables from, we can add that to the list we add as a parameter to the columns argument. See this notebook for all code examples in this tutorial about creating dummy variables in Python. For more Python Pandas tutorials, check out this page.
Conclusion: Dummy Coding in Python
In this post, we have learned how to do dummy coding in Python using Pandas get_dummies() method. More specifically, we have worked with categorical data with two levels and categorical data with three levels. Furthermore, we have learned how to add and remove prefixes from the new columns created in the dataframe.
Additional Resources
Here are a couple of additional resources to dig deeper into dummy coding:
- Dummy Variable (Wikiversity)
- Dummy Coding: the how and why
- Factorial Designs and Dummy Coding (Peer-reviewed article)
- Use of dummy variables in regression equations (Peer-reviewed article)
- An Introduction to Categorical Data Analysis (statistics book)
Python Tutorials:
- Coefficient of Variation in Python with Pandas & NumPy
- Python Scientific Notation & How to Suppress it in Pandas & NumPy
- Pandas Count Occurrences in Column – i.e. Unique Values
- How to use Python to Perform a Paired Sample T-test

Thanks for your post Erik, quite easy to understand and implement after reading.
However, I’d like to point out some issues I found while reading:
– What is a Dummy Variable?: there is duplicated text in this block.
– tags: some of your code blocks end with a malformed closing tag for code, i.e:
df_dummies = pd.get_dummies(df, prefix=’Rank’, prefix_sep=’.’,
columns=[‘rank’])
df_dummies.head()code>
Hope this helps!
Hey Alex! Thanks for your kind comments. Also, thanks for spotting these errors.
Thanks for the precise explanation.
Hey Santosh! I am glad you liked the post. Thanks for your comment! Have a nice day!
Amazing notebook and article!
Is there a way to one hot encode multiple columns like you did in the last example of the linked notebook, except provide a unique prefix for each column I am “one hot encoding”
Hey Rehankhan,
Thank you for your kind comment. I am glad you liked the article and the notebook with the get_dummy() code examples. Now, if I understand your question correctly, you can add your unique prefixes to the prefix parameter. For example, in the last example (in the Notebook) you can do like this:
Of course, the prefix_sep can be used to separate the prefix from the dummy variable name (e.g., p1_AssocPorf, and so on, can be obtained by adding
prefix_sep='_'Is this what you are after?
Have a nice day,
Best,
Erik
Can you help me with creating a function to create dummy variables
Hi Ajjay,
Is this tutorial not helping you to write a function to create indicator variables? If not, you can give me a short description of your data, and the problem you have. This way it’s easier for me to help you out.
If I use my browser’s find feature to search “in python”, it will give me exactly 40 counts. I am curious that why you were not sure you were writing tutorial for python?
Well, thank you for finding this and pointing this out. I’ve removed a couple of these as it probably affects the readability of the post. Well spotted!
Best,
Erik
Thanks for your post Erik! Really helped me in understanding dummy variables and with my assignment. Cheers 🙂
Hey Trevor,
Thanks for your comment! I am glad it helped,
Good luck with your studies,
Best,
Erik
Thanks for the good explanation! It helped me a lot.
John
hello , thank you for this amazing articel , i’ve learned a lot.
from iran
Hey Arash. Thanks for your kind comment. I am glad the R tutorial helped-