In this post, we will learn how to use Pandas drop_duplicates() to remove duplicate records and combinations of columns from a Pandas dataframe. That is, we will delete duplicate data and only keep the unique values.
This Pandas tutorial will cover the following; what’s needed to follow the tutorial, importing Pandas, and how to create a dataframe from a dictionary. After this, we will get into how to use Pandas drop_duplicates() to drop duplicate rows and duplicate columns.
Note, that we will drop duplicates using Pandas and Pyjanitor, which is a Python package that extends Pandas with an API based on verbs. It’s much like working with the Tidyverse packages in R. See this post on more about working with Pyjanitor. However, we will only use Pyjanitor to drop duplicate columns from a Pandas dataframe.
- Data Cleaning in Python with Pandas and Pyjanitor is a post where you will learn more about working with Pyjanitor.
Table of Contents
- Prerequisites
- Creating a Dataframe from a Dictionary
- Highlighting the Duplicated Row in Pandas Dataframe
- Pandas drop_duplicates(): Deleting Duplicate Rows:
- Pandas Drop Duplicates with Subset
- Pandas Drop Duplicated Columns using Pyjanitor
- Conclusion: Using Pandas drop_duplicates()
- Resources
Prerequisites
As usual in the Python tutorials focusing on Pandas, we need to have both Python 3 and Pandas installed. Python can be installed by downloaded here or by installing a Python distribution such as Anaconda or Canopy. If we install Anaconda, for instance, we’ll also get Pandas. Obviously, if we want to use Pyjanitor, we also need to install it: pip install pyjanitor. Note, this post explains how to install, use, and upgrade Python packages using pip or conda. That said, now we can continue the Pandas drop duplicates tutorial.
At times, when we install Python packages, we may also notice that we need to update pip. Now, updating pip is quite easy using conda or pip.
Creating a Dataframe from a Dictionary
In this section, of the Pandas drop_duplicates() tutorial, we are going to create a Pandas dataframe from a dictionary. First, we are going to create a dictionary and then we use pd.Dataframe() to create a Pandas dataframe.
import pandas as pd
# Creating a Dict
data = {'FirstName':['Steve', 'Steve', 'Erica',
'John', 'Brody', 'Lisa', 'Lisa'],
'SurName':['Johnson', 'Johnson', 'Ericson',
'Peterson', 'Stephenson', 'Bond', 'Bond'],
'Age':[34, 34, 40,
44, 66, 51, 51],
'Sex':['M', 'M', 'F', 'M',
'M', 'F', 'F']}
# Pandas dataframe from dict:
df = pd.DataFrame(data)Code language: Python (python)Highlighting the Duplicated Row in Pandas Dataframe
Now, before removing duplicate rows we are going to print the dataframe with the highlighted rows. Here, we use the Styling API which enables us to apply conditional styling. In the code chunk below, we create a function that checks for duplicate rows and then sets the color of the rows to the color red.
def highlight_dupes(x):
df = x.copy()
df['Dup'] = df.duplicated(keep=False)
mask = df['Dup'] == True
df.loc[mask, :] = 'background-color: red'
df.loc[~mask,:] = 'background-color: ""'
return df.drop('Dup', axis=1)
df.style.apply(highlight_dupes, axis=None))Code language: PHP (php)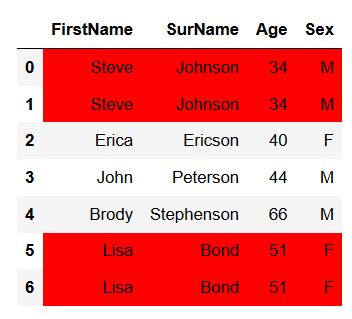
Note, this above code was found on Stackoverflow and adapted to the problem of the current post.
Finally, before going on and deleting duplicate rows we can use Pandas groupby() and size() to count the duplicated rows:
df.groupby(df.columns.tolist(),as_index=False).size()Code language: Python (python)
Learn more about grouping categorical data and describing the data using the groupby() method:
Pandas drop_duplicates(): Deleting Duplicate Rows:
In this section, we are going to drop rows that are the same using Pandas drop_duplicates(). This is very simple; we just run the code example below.
df_new = df.drop_duplicates()
df_newCode language: Python (python)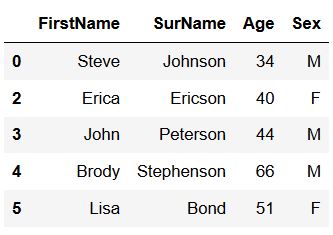
Now, in the image above we can see that the duplicate rows were removed from the Pandas dataframe but we can count the rows, again to double-check.
df_new.groupby(df_new.columns.tolist(), as_index=False).size()Code language: Python (python)
Pandas Drop Duplicates with Subset
If we want to remove duplicates from a Pandas dataframe, where only one or a subset of columns contains the same data, we can use the subset argument. When using the subset argument with Pandas drop_duplicates(), we tell the method which column, or list of columns, we want to be unique. Now, before working with Pandas drop_duplicates(), again, we need to create a new example dataset:
df_new = df.drop_duplicates(subset=subset=['FirstName', 'SurName'])
df_newCode language: Python (python)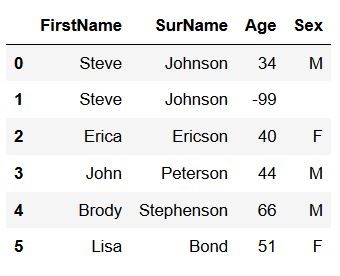
Furthermore, we can also specify which duplicated row we want to keep. If we don’t change the argument, it will remove the first:
df_new = df.drop_duplicates(subset=['FirstName', 'SurName'])
df_newCode language: JavaScript (javascript)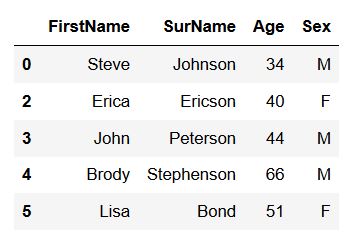
If we, on the other hand, set it to “last” we will see a different result:
df_new = df.drop_duplicates(keep='last', subset=subset=['FirstName', 'SurName'])
df_newCode language: Python (python)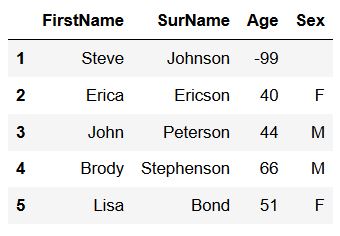
In the next section, we are going to delete duplicate columns using Pyjanitor. Note it is quite easy to install Python packages, such as Pyjanitor, with pip: pip install pyjanitor. If pip is of an old version, see the post about how to upgrade pip.
Pandas Drop Duplicated Columns using Pyjanitor
In the last section of this Pandas drop duplicated data tutorial, we will work with Pyjanitor to remove duplicated columns. This is very easy, and we do this with the drop_duplicate_columns() method and the column_name argument. Now, before dropping duplicated columns, we create a dataframe from a dictionary:
import pandas as pd
data = {'FirstName':['Steve', 'Steve', 'Erica',
'John', 'Brody', 'Lisa', 'Lisa'],
'SurName':['Johnson', 'Johnson', 'Ericson',
'Peterson', 'Stephenson', 'Bond', 'Bond'],
'Age':[34, 34, 40,
44, 66, 51, 51],
'Sex':['M', 'M', 'F', 'M',
'M', 'F', 'F'],
'S':['M', 'M', 'F', 'M',
'M', 'F', 'F']}
df = pd.DataFrame(data)
dfCode language: Python (python)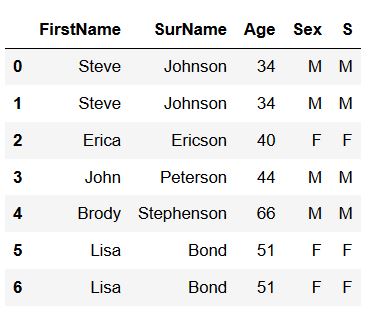
As can be seen in the image above, we have the duplicated columns “Sex” and “S” and we remove them now:
df = df.drop_duplicate_columns(column_name=’S’)Conclusion: Using Pandas drop_duplicates()
In conclusion, using Pandas drop_duplicates was very easy, and in this post, we have learned how to:
- Delete duplicated rows
- Delete duplicated rows using a subset of columns
- Delete duplicated columns
The two first things we learned were accomplished using drop_duplicates() in Pandas, and the third thing was done with Pyjanitor.
Resources
Here are some great Python tutorials that will be helpful on your learning journey:
- Coefficient of Variation in R
- Pandas Count Occurrences in Column – i.e. Unique Values
- Python Scientific Notation & How to Suppress it in Pandas & NumPy
- Pandas Convert Column to datetime – object/string, integer, CSV & Excel
- How to Convert JSON to Excel in Python with Pandas

Nice post. There is a typo in this line…
df.style.apply(highlight_dupes, axis=None)
Thanks for your comment. Glad you liked the post. I’ve corrected the typo, thanks for spotting this for me!
Best,
Erik