In this post, we will learn how to create a binder so that our data analysis, for instance, can be fully reproduced by other researchers. That is, here we will learn how to use a tool called Binder for reproducible research.
In previous posts, we have learned how to carry out data analysis (e.g., ANOVA) and data visualization (e.g., Raincloud plots) using Python. The code we have used have been uploaded in the forms of Jupyter Notebooks.
For users of R Statistical Environment;
Although this is great, we also need to make sure that we share our computational environment so that our code can be re-run and produce the same output. That is, to have a fully reproducible example, we need a way to capture the different versions of the Python packages we’re using.
Although uploading our code, and data, sharing links to online repositories (for instance GitHub or the Open Science Framework) is good. However, this will not enable other researchers to run and interact with this material. It can be somewhat cumbersome to recreate the exact environment that is required to run another researcher’s analysis.
This is where Binder can make a difference; it enables us to reproduce our exact Python environment, with a Jupyter Notebook Online, so that other researchers can reproduce our exact workflow as well as change it.
Table of Contents
- Outline
- What is Binder
- Requirements:
- How to Use Git
- Reproducible Data Visualization and Analysis using Binder
- Creating a Jupyter Notebook Online Using Binder.
- Binder and RStudio
- Summary
- Tutorials
Outline
In this post, we will focus on how to use Binder for reproducible research so it will not cover any technical details about Binder. We will, however, start out with learning briefly about what Binder actually is. Following learning more about Binder, we will go into a quick tour of how to use Git. Now, we need to know this because we are going to use Git together with Binder to create our reproducible environment. In the section after we learned about Git, we will get an example of how to use git together with Binder. First, we create a Jupyter notebook using a couple of Python packages to import data, explore the imported data, carry out data analysis etc. After this, we create our push our Jupyter notebook to Github using git. Finally, we create our Binder from this git repository.
What is Binder
As previously mentioned, Binder enables us to create custom computing environments. These environments can be shared and used by many users. For instance, our data analysis can be run, by another researcher, by following a link to a Jupyter Notebook online. Binder is powered by BinderHub, which is an open-source tool that deploys the Binder service in the cloud.

In this Binder tutorial, we will use one of these free to use deployment; mybinder.org.
So how does Binder work? Binder works by pulling a repository that we set up on GitHub into a Docker container. Docker packages our data, code and all its dependencies, that we have specified in a file, into a docker container. This ensures that our application works seamlessly in any environment.
Requirements:
In this Binder tutorial, we start with doing data visualization, and then we carry out parametric analysis using Python. The tools that are needed for following this Binder guide are as follows:
- Git and a Github account
- Python 3.7 and the following Python packages:
- Matplotlib
- Seaborn
- SciPy
- NumPy
- Pandas
- Pingouin
All packages above, except for Pingouin, are included in the Python distribution Anaconda. If we need to install Pingouin on our local computer we can use conda:
conda install -c conda-forge pingouinCode language: Bash (bash)Note, all packages will be installed when we create the Binder later. As you also may understand, you don’t need to use any of these packages to create a Binder. All you need is basically git and a e.g. github account.
How to Use Git
Before creating our first Binder environment we need to create a GitHub account and install Git. Click here to skip this part and start directly with setting up the Binder.
Step 1: Download Git
Go to https://git-scm.com/downloads and download git, click on the downloaded file, and follow the instructions.
The next thing we need to do is to configure git. Start git bash (e.g., press the win key and type “git bash” ).
In the Git Bash command prompt we set up git:
git config --global user.name "Your name here"
git config --global user.email "[email protected]"Code language: Bash (bash)Step 2: Create a GitHub Repository
We are now going to create a directory for our repository. Again, we can use Git Bash, and type the following commands:
cd Documents
mkdir Binder
cd Binder
mkdir bindtut
cd bindtutCode language: Bash (bash)In this new folder we can initialize a git repository:
git initCode language: Bash (bash)Step 3: Create the environment and a README files
In the next step, we are going to create our environment.yml and README.md files. The file environment.yml is the environment configuration file that specifies an Anaconda environment (here’s a link to the one used in this Binder tutorial).
Creating the environment.xml file:
First, we open up a text editor, in this case, Atom.io, and create a new file (File > New file):
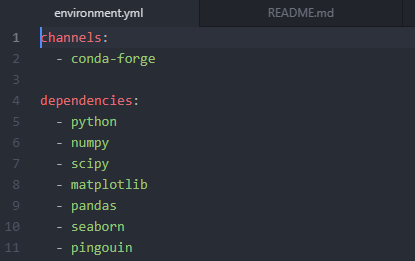
Next, we are going to save this file as “environment.yml” in the directory we previously created.
Creating the README.md file:
In the text editor, we now create another file (remember, File > New File) and save it as READM.md. In this file we add the following text:
## How to Use Binder for Reproducible Research
This is an example README.md file for the tutorial on how to use Binder fore reproducible research in python.
Note, the above is an example README.md file for the tutorial on how to use Binder for reproducible research in python. Naturally, for a real science project, we would write a more descriptive README.md.
Step 4: Add the Files and Create a Commit
We are now ready to commit our files. Open up Git Bash, again, and type “git add .”, press enter, and then type ‘“git commit -m “Created the binder Anaconda environment and README files”’.
git add.
git commit -m "Created the binder Anaconda environment and README files"Code language: Backus–Naur Form (bnf)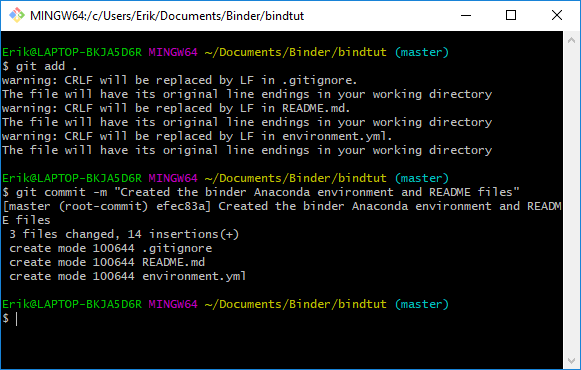
Step 5: Create a new repository on GitHub
Now we are going to create a new repository on GitHub. First, go to the GitHub home page and press the green ‘+ New repository button:
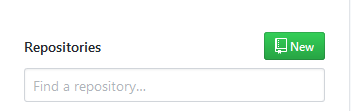
After we have clicked the button, GitHub will ask us to name the repository. In this Binder example we leave out the description and give the repository the name “bindertut”:
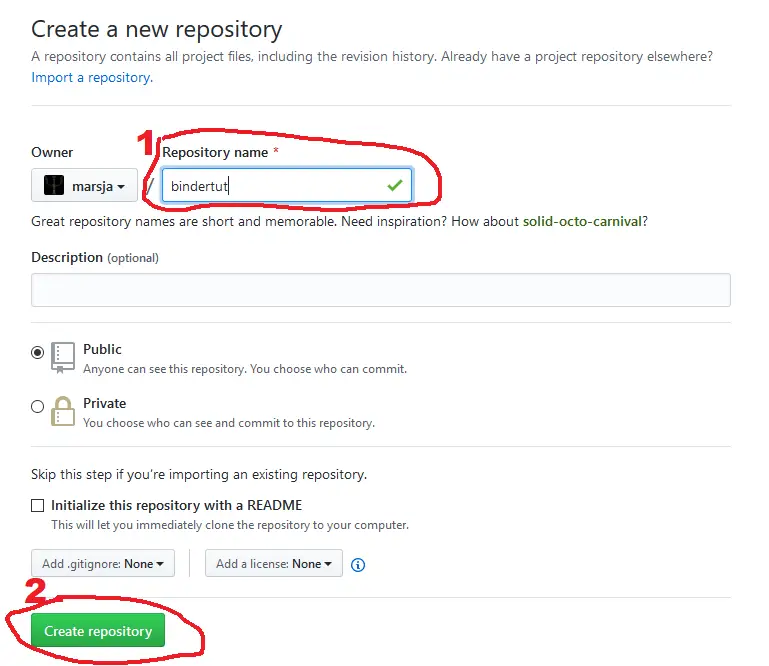
When we all information filled in, we press the ‘Create repository’ button to make our new repository.
Note, we have already created a new repository locally and, thus, we want to push that onto GitHub:
git remote add origin [email protected]:marsja/bindertut.git
git push -u origin masterCode language: Bash (bash)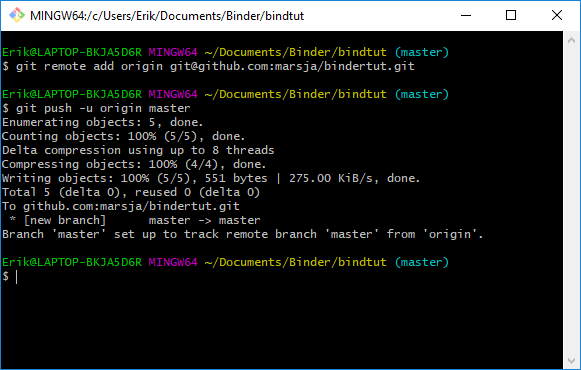
Remember to change the username (i.e., marsja to yours). For more guides on how to use Github see here.
Reproducible Data Visualization and Analysis using Binder
In the next code examples, we are going to create a bar plot and a line plot using Seaborn. We are also loading the data, from a URL, using Pandas. As this is a tutorial on how to use Binder for reproducible research, the code is not explained.
Creating a Jupyter Notebook
First, we need to create a Jupyter Notebook. We can do this by starting the Anaconda Navigator and pressing “launch”:

Now, this will start Jupyter in our preferred web browser. The next thing we need to do is to create a new Jupyter Notebook. On the right side press new and select “Python 3”:
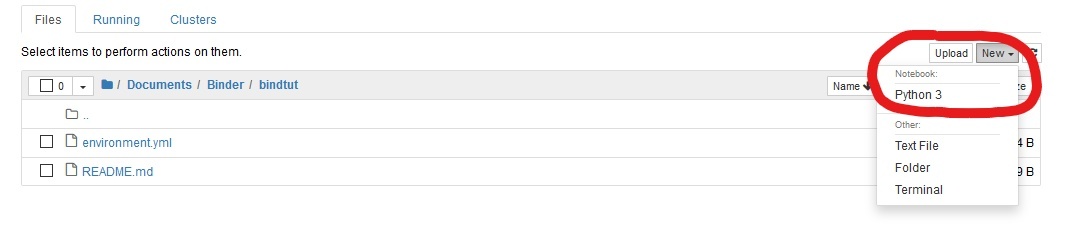
Python Code Example:
%matplotlib inline
import pandas as pd
# Suppress warnings
import warnings
warnings.filterwarnings('ignore')
# Getting the data
data = "https://vincentarelbundock.github.io/Rdatasets/csv/carData/OBrienKaiser.csv"
# Loading the data into a Pandas dataframe
df = pd.read_csv(data, index_col=0)
# Using Pandas head to check the first 5 rows of the dataframe
df.head()Code language: Python (python)For more on how to work with Python Pandas:
- A Basic Pandas Dataframe Tutorial for Beginners
- Python Pandas Groupby Tutorial
- Exploratory Data Analysis in Python Using Pandas, SciPy, and Seaborn
As pingouin requires the data to be in long format, we need to use Pandas wide_to_long to reshape the dataframe:
df["id"] = df.index
df_long = pd.wide_to_long(df, ["pre", "post", "fup"],
i=["id", "gender", "treatment"],
j='hour', sep=".").reset_index()
df_long = pd.melt(df_long,id_vars=["id", "gender", "treatment", "hour"],
var_name='phase', value_name='value')
df_long.head()¨Code language: Python (python)Box Plots in Python using Seaborn
We are not going into details on how to use Seaborn. However, we will create a box plot using Seaborn’s catplot method:
import seaborn as sns
g = sns.catplot(x="phase", y="value", kind="box", hue="treatment", data=df_long)Code language: Python (python)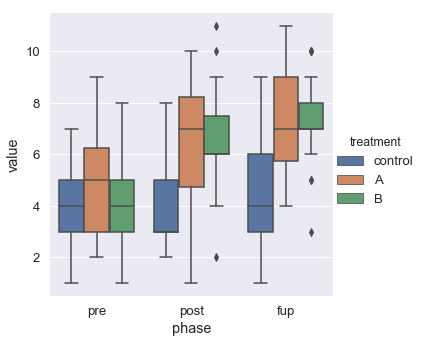
Notice, with some hacks it is possible to change the Seaborn figsize (e.g., using Matplot pyplot). In the next subsection, we will create an line plot.
Line Plots using Seaborn
Next, we create a line plot, using the Seaborn lineplot method.
ax = sns.lineplot(x="phase", y="value", hue="treatment",
data=df_long)Code language: Python (python)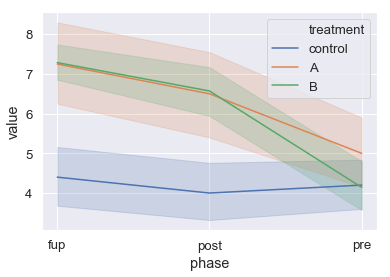
If you are interested in learning more about data visualization using Seaborn see the posts 9 Data Visualization Techniques You Should Learn in Python and How to Make a Scatter Plot in Python using Seaborn.
Two-Way Mixed ANOVA in Python
Now we can use Pingouin to carry out a Two-Way Mixed ANOVA in Python.
from pingouin import mixed_anova
aov = mixed_anova(dv='value', between='treatment',
within='phase', subject='id', data=df_long)
print(aov)Code language: Python (python)For more about ANOVA in Python:
There’s one final step before we go on and create our Binder. We need to add the Jupyter Notebook to the Github repository, commit it, and then push it:
git add .
git commit -m “Done with the data analysis”
git push -u origin masterCode language: Python (python)Creating a Jupyter Notebook Online Using Binder.
Finally, we are ready to create our Binder. This is fairly simple, we open up a new tab in our browser and type “https://gke.mybinder.org/” and hit enter.
Creating a Binder Step-By-Step
Now we’re ready to create our reproducible computational environment (Jupyter Notebook) using Binder. It’s actually very easy and requires two steps:
1 Adding the URL to the GitHub Repo
First, we need to add the url to the GitHub repository. For example, in my case it’s “https://github.com/marsja/bindertut”. We are now ready for the next step:
2 Pressing the “launch” button
In the second step, we are just going to pres the launch button. See the image below for the two steps.
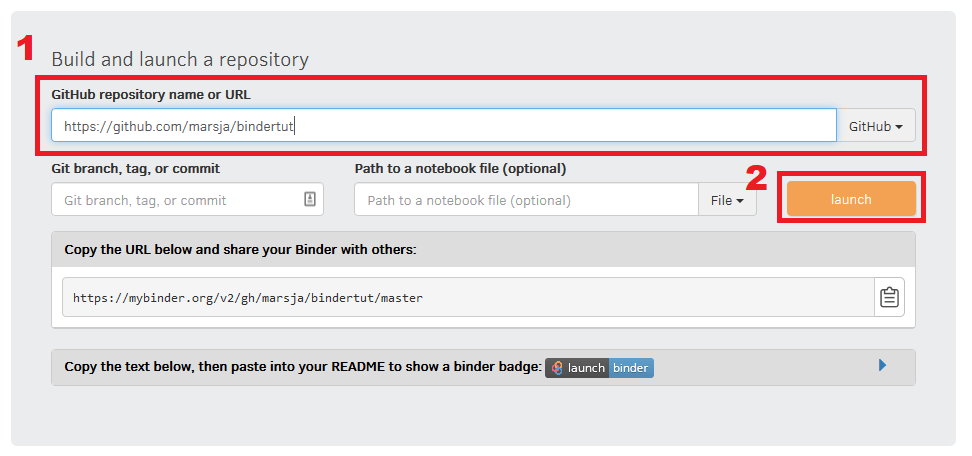
Now we have to sit back, make some coffee, and wait for it to be done. Finally, we’ll get a link that we can share with other researchers.
Finally, it’s important to remember that any changes in the Jupyter Notebook online, on Binder, will not be saved. In fact, the notebooks will be automatically shut down after 10 minutes of inactivity. Of course, the Binder can be updated. In fact, all we need to do is go back to our the repository, make changes, commit, and push back to GitHub
Binder and RStudio
Binder, Github, and mybinder can, of course, also be used to create a reproducible R environment. If we are carrying out our data analysis using R we can create a fully reproducible RStudio environment instead of a Jupyter Notebook. Here’s a tutorial on how to use Binder together with R and Rstudio.
Summary
In this tutorial, we have learned how to set up git, use GitHub together with Binder for Reproducible data visualization and analysis. Furthermore, we used Seaborn and Pingouin for visualizing and analyzing data in a Jupyter Notebook. This Notebook, along with the GitHub repository we created, can be found online here.
Tutorials
- Adding New Columns to a Dataframe in Pandas (with Examples)
- How to Add a Column to a Dataframe in R with tibble & dplyr
