In this post, we learn how to use Pandas to calculate a cumulative sum by group, a sometimes important operation in data analysis. Consider a scenario in cognitive psychology research where researchers often analyze participants’ responses over multiple trials or conditions. Calculating the cumulative sum by group may be important to understand the evolving trends or patterns within specific experimental groups. For instance, tracking the cumulative reaction times or accuracy rates across different experimental conditions can show us insightful patterns. These patterns, in turn, can shed light on the cognitive processes of interest in our study/studies.

Pandas, a widely used data manipulation library in Python, simplifies this process, providing an effective mechanism for computing cumulative sums within specific groups. We will see how this functionality streamlines complex calculations as we get into the examples. Pandas enhance our ability to draw meaningful insights from grouped data in diverse analytical contexts.
Table of Contents
- Outline
- Prerequisites
- Understanding Cumulative Sum
- Synthetic Data
- Using Pandas to Calculate Cumulative Sum
- Pandas Cumulative Sum by Group: Examples
- Summary
- Resources
Outline
The structure of the current post is as follows. First, we quickly look at what you need to follow the post. Next, we had a brief overview of cumulative sum in Pandas. Here, we introduce the cumsum() function. Next, we created a practice dataset and calculated the cumulative sum using Pandas cumsum() on this. First, without grouping, then we moved into more advanced applications with cumulative sums by group, exploring examples that illustrate its versatility and practical use in data analysis. We conclude by summarizing key takeaways.
Prerequisites
Before we explore the cumulative sum by group in Pandas, ensure you have a basic knowledge of Python and Pandas. If not installed, consider adding the necessary libraries to your Python environment to follow along seamlessly (i.e., Panda). Familiarity with groupby operations in Pandas will be particularly beneficial. The cumulative sum operation often involves grouping data based on specific criteria.
Understanding Cumulative Sum
Understanding cumulative sum can be important in data analysis. This especially true when exploring trends, aggregating data, or tracking accumulative changes over time. Cumulative sum, or cumsum, is a mathematical concept involving progressively adding up a sequence of numbers. In Pandas, this operation is simplified using the cumsum() function.
Syntax of Pandas cumsum()
The cumsum() function in Pandas has several parameters that enables some customization based on specific requirements:
axis: Specifies the axis along which the cumulative sum should be computed. The default isNone, indicating the operation is performed on the flattened array.skipna:A Boolean value that determines whether to exclude NaN values during the computation. If set toTrue(default),NaNvalues are ignored, while if set to False, they are treated as valid input for the sum.*args,**kwargs: Additional arguments and keyword arguments that can be passed to customize the function’s behavior further.
Understanding these parameters is important to customize the cumulative sum operation to our specific needs, providing flexibility in dealing with different data types and scenarios.
Before learning how to do the group-specific cumulative sum, let us explore how to perform a basic cumulative sum without grouping. This foundational knowledge will serve as a stepping stone for our subsequent exploration of the cumulative sum by the group in Pandas. But first, we will create some data to practice.
Synthetic Data
Let us create a small sample dataset using Pandas to practice cumulative sum.
import pandas as pd
import numpy as np
# Create a sample dataframe with a grouping variable
data = {
'Participant_ID': [1, 1, 1, 2, 2, 2, 3, 3, 3],
'Hearing_Status': ['Normal', 'Normal', 'Normal', 'Impaired', 'Impaired', 'Impaired', 'Normal', 'Normal', 'Normal'],
'Task': ['Reading Span', 'Operation Span', 'Digit Span'] * 3,
'Trial': [1, 2, 3] * 3,
'WM_Score': [8, 15, 4, 12, np.nan, 7, 9, 10, 8],
'Speech_Recognition_Score': [75, 82, 68, np.nan, 90, 76, 88, 85, np.nan]
}
df = pd.DataFrame(data)Code language: Python (python)This dataset simulates cognitive psychology tests where participants undergo different tasks (reading, operation, digit span) over multiple trials, with associated working memory (WM) and speech recognition scores. Some scores intentionally include NaN values to demonstrate handling missing data.
The dataframe structure is organized with columns for ‘Participant_ID’, ‘Task’, ‘Trial’, ‘WM_Score’, and ‘Speech_Recognition_Score’. We also have the grouping variable ‘Hearing_Status’. Each row represents a participant’s performance in a specific task during a particular trial.
This dataset will be the basis for practicing using Pandas to calculate cumulative sum by group. First, however, we will just learn how to use the cumsum() function.
Using Pandas to Calculate Cumulative Sum
Here is an example of using Pandas cumsum() without grouping:
# Calculate cumulative sum without grouping
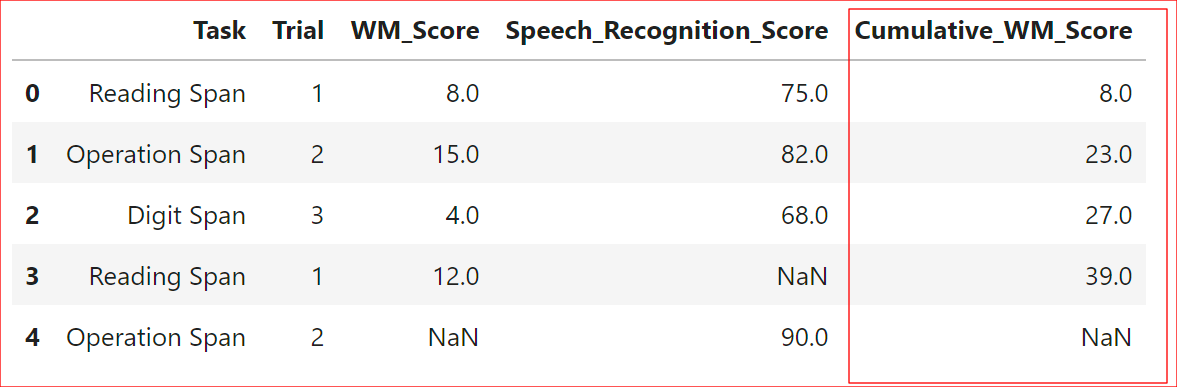
df['Cumulative_WM_Score'] = df['WM_Score'].cumsum()
df['Cumulative_SPIN_Score'] = df['Speech_Recognition_Score'].cumsum()Code language: Python (python)In the code chunk above, we used the cumsum() function from Pandas to compute the cumulative sum of the ‘WM_Score’ and ‘Speech_Recognition_Score’ columns in the dataframe. The .cumsum() method is applied directly to the selected columns, creating new columns, ‘Cumulative_WM_Score’ and ‘Cumulative_Speech_Recognition_Score’. This operation calculates the running total of the scores across all rows in the dataset. Here are the rows 2 to 7 selected with Pandas iloc and the five first rows printed:
Pandas Cumulative Sum by Group: Examples
Example 1: Cumulative Sum by Group with One Column
Let us start by looking at the basic application of cumulative sum within a group for a single column using Pandas. This example will consider the cumulative sum of working memory scores (‘WM_Score’) within the different groups.
df['Cum_WM_Score'] = df.groupby('Hearing_Status')['WM_Score'].cumsum()Code language: Python (python)In the code chunk above, we are using Pandas to create a new column, ‘Cum_WM_Score,’ in the DataFrame df. This new column will contain the cumulative sum of the ‘WM_Score’ column within each group defined by the ‘Hearing_Status’ column. The groupby() function is employed to group the data by the ‘Hearing_Status’ column, and then cumsum() is applied to calculate the cumulative sum for each group separately. The result is a dataframe with the original columns and the newly added ‘Cum_WM_Score’ column, capturing the cumulative sum of working memory scores within each hearing status group.
Example 2: Cumulative Sum by Group with Multiple Columns
Expanding on the concept, we can compute the cumulative sum for multiple columns within groups:
cols_to_cumsum = ['WM_Score', 'Speech_Recognition_Score']
df[cols_to_cumsum] = df.groupby('Hearing_Status')[cols_to_cumsum].cumsum()Code language: Python (python)In the code snippet above, we again used Pandas to perform a cumulative sum on selected columns (i.e., ‘WM_Score’ and ‘Speech_Recognition_Score’) within each group. This is an extension of the concept introduced in Example 1, where we applied cumsum() on a single column within groups.
Here, we use the groupby() function to group the data by the ‘Hearing_Status’ column and then apply cumsum() to the specified columns using cols_to_cumsum. The result is an updated dataframe df with cumulative sums calculated for the chosen columns within each hearing status group.
Summary
In this post, we looked at using Pandas to calculate cumulative sums by group, a crucial operation in data analysis. Starting with a foundational understanding of cumulative sums and their relevance, we explored the basic cumsum() function. The introduction of group-specific calculations brought us to Example 1, showcasing how to compute cumulative sums within a group for a single column. Building on this, Example 2 extended the concept to multiple columns, demonstrating the versatility of Pandas’ cumulative sum by group.
We navigated through the syntax and application of the cumsum() function, gaining insights into handling missing values and edge cases. Working with a sample dataset inspired by cognitive psychology, we looked at practical scenarios for cumulative sum by group. The approach used in Examples 1 and 2 provides a foundation for applying custom aggregation functions and tackling diverse challenges within grouped data.
Feel free to share this tutorial on social media, and if you find this post valuable for your reports or papers, include the link for others to benefit!
Resources
- Descriptive Statistics in Python using Pandas
- Coefficient of Variation in Python with Pandas & NumPy
- Create a Correlation Matrix in Python with NumPy and Pandas
