This tutorial covers the integration between R and Python using the rpy2 package. Discover how to bridge the gap between these two languages, enabling you to harness both strengths for enhanced data analysis and visualization. This rpy2 tutorial guides you through its installation, configuration, and practical usage.
Table of Contents
- Outline
- How to Install rpy2
- rpy2 Example: How to Call R from Python
- Rpy2 Video Tutorial: Displaying R plots inline in Jupyter Notebooks
- R Plots in Jupyter Notebooks Using the rmagic Extension
- Conclusion: rpy2 tutorial
Outline
In this tutorial, we will learn how to use rpy2 to install r packages and run r functions to conduct data analysis and visualization. We will learn how to use the r-packages ‘afex‘ and ‘emmeans‘, using Python and rpy2. Finally, we will also learn how to display R plots in Jupyter notebooks using rpy2, using two different methods.
Obviously, rpy2 requires that we have both R (version +3.2.x) and Python (versions 2.7 and 3.X) installed. Pre-compiled binaries are available for Linux and Windows (unsupported and unofficial, however).
Rpy2 is a straightforward, easy-to-use package allowing us to run R from Python. That is, this handy Python package enables us to enjoy the elegance of the Python programming language at the same time as we get access to the rich graphical and statistical capabilities of the R statistical programming environment.
How to Install rpy2
First, we start the tutorial by installing rpy2. There are two very easy ways to install Python packages such as rpy2.
1. Install rpy2 using pip
sudo pip install rpy2Code language: Bash (bash)Note if you can use pip to install a specific version of rpy2 by adding “==” followed by the version to the above code chunk.
2. Install rpy2 using conda
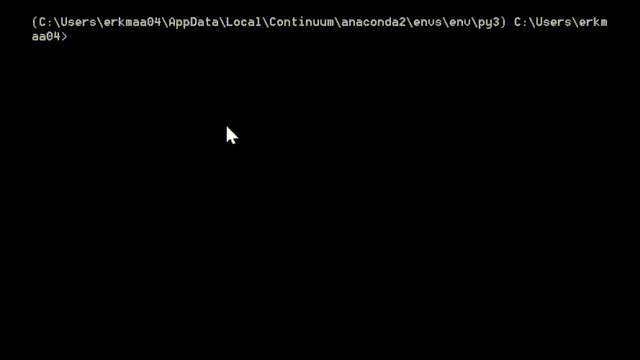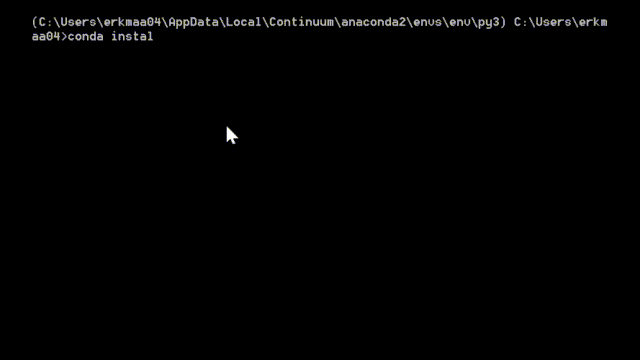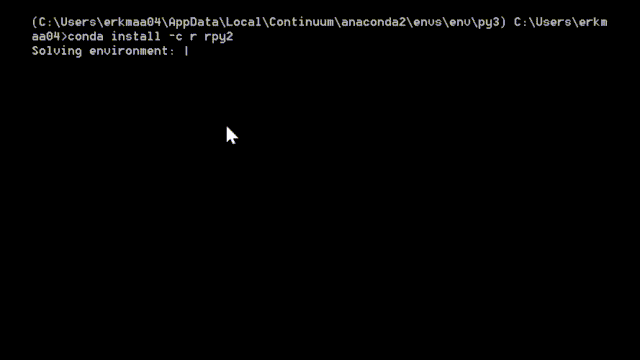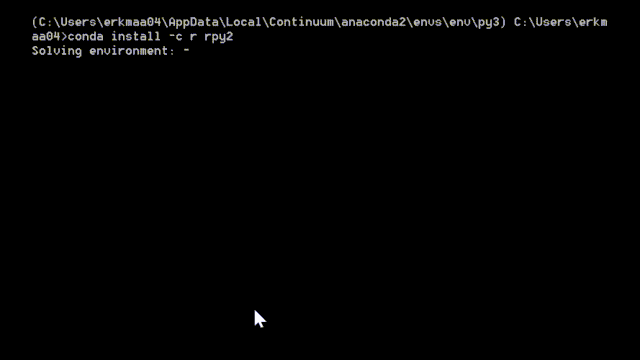
If you are a Windows and/or have Anaconda Python distribution installed here’s how you can install rpy2:
rpy2 Example: How to Call R from Python
Now when we have a working installation of rpy2, we continue the R in Python tutorial with importing the methods that we are going to use. In the following rpy2 example we are going to use ‘afex’ to do the within-subject ANOVA and ’emmeans’ to do the follow-up analysis.
import rpy2.robjects as robjects
import rpy2.robjects.packages as rpackages
from rpy2.robjects.vectors import StrVectorCode language: Python (python)Before we continue with the rpy2 example, we also need to check whether the needed r packages are installed. In the example below we are calling r from Python to use the r package utils to install the needed r packages. The code is now updated thanks to comments on my YouTube Channel (the variable have_packages is removed. Thanks Sergey).
How to Install r packages Using rpy2
packageNames = ('afex', 'emmeans')
utils = rpackages.importr('utils')
utils.chooseCRANmirror(ind=1)
packnames_to_install = [x for x in packageNames if not rpackages.isinstalled(x)]
# Running R in Python example installing packages:
if len(packnames_to_install) > 0:
utils.install_packages(StrVector(packnames_to_install))Code language: Python (python)For this tutorial, we use a data set from the package Psych. In this case, we use the r-function read.table to get the data. Note how we use the class robjects from rpy2 and with a string argument we call read.table:
data = robjects.r('read.table(file =
"http://personality-project.org/r/datasets/R.appendix3.data", header = T)')
data.head()Code language: Python (python)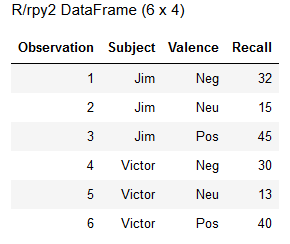
Repeated Measures ANOVA using rpy2
In this part of the rpy2 tutorial, we will carry out the actual analysis. In the example below, we are actually using R in Python! More specifically, we are importing the r package needed to carry out our ANOVA for within-subjects design. When this is done, we will use the function aov_ez to conduct the analysis.
# Running R in Python to carry out data analysis:
afex = rpackages.importr('afex')
model = afex.aov_ez('Subject', 'Recall', data, within='Valence')
print(model)Code language: Python (python)
Follow-up analysis
Typically we are interested in following up on the main effect, and with rpy2, we can do that using the r-package ’emmeans’. First, we need to import the package and then we do a pairwise contrast and adjust for familywise error using Holm-Bonferroni correction.
# R in Python multiple comparisons:
emmeans = rpackages.importr('emmeans',
robject_translations = {"recover.data.call": "recover_data_call1"})
pairwise = emmeans.emmeans(model, "Valence", contr="pairwise", adjust="holm")Code language: PHP (php)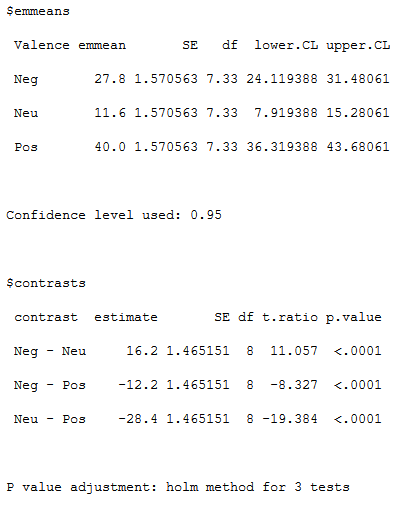
That was easy, right. Now we have learned how to use R in Python! Rpy2 is relatively easy to use I don’t think it will replace learning R. That is, you will have to know some R to use it to call R from Python. However, if you are a Python programmer and want to use available R-scripts, it might be useful and hopefully, this rpy2 tutorial has made it somewhat easier for you! Noteworthy, I am not aware of any Python implementations of rmANOVA (except for the linear-mixed effects approach maybe). That is why I learned how to use rpy2 first; to use Python, and R, to conduct the analysis. The above code examples can be found in this Jupyter Notebook.
Rpy2 Video Tutorial: Displaying R plots inline in Jupyter Notebooks
In this video, we will learn how to display R plots in Jupyter Notebooks. In these two rpy2 examples we are creating a barplot (using R graphics) and a scatterplot (using ggplot2)!
R Plots in Jupyter Notebooks Using the rmagic Extension
In the last example, we will learn an alternative method for displaying R plots in Python. Here, we use the Jupyter extension magic.
%load_ext rpy2.ipython
%Rdevice pngCode language: Python (python)In the code example above, we load the extension rmagic to run R in Python and jupyter notebooks. Next, we are setting the device to png.
After we have loaded the rmagic extension, we can reproduce the first plot in the above YouTube video with fewer lines of code:
%%R
barplot(c(1,3,2,5,4), ylab="value")Code language: JavaScript (javascript)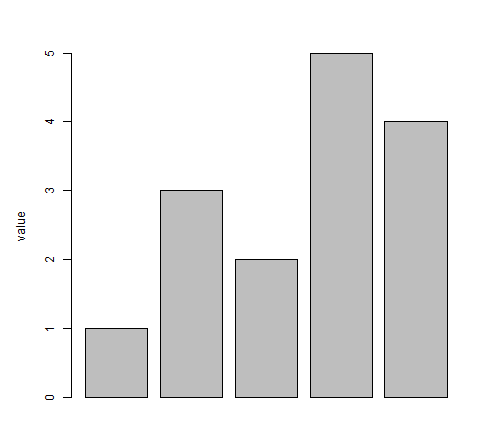
Note we added the %%R and Jupyter will after that use rpy2 to run R functions. In the final example we are (nearly) reproducing the second plot in the above YouTube video.
%%R
require(ggplot2)
gg <- ggplot(mtcars, aes(x=wt, y=mpg)) + geom_point(aes(colour='qsec')) + theme_bw()
ggCode language: Python (python)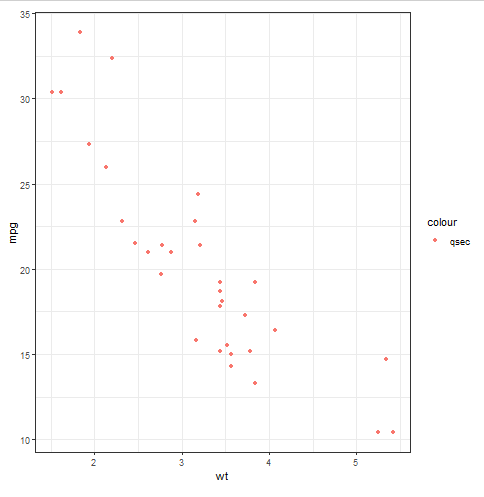
As can be seen in the code chunk above, we can also load the r package(s) we want to work with and use them much as we do in R. Read the tutorial on how to make scatter plots in R if you are interested in how to create this type of figure in R.
Update: In this rpy2 tutorial, you learned how to do a repeated-measures ANOVA with Python and R. I have now found a Python package that allows Python ANOVA for within-subjects design (i.e., Python native); see my tutorial Repeated Measures ANOVA using Python.
Conclusion: rpy2 tutorial
In conclusion, this rpy2 tutorial has provided a comprehensive understanding of the rpy2 package, enabling integration between R and Python for enhanced data analysis and visualization. You have learned how to install rpy2 using pip and conda. Moreover, you have explored practical examples of calling R from Python, installing R packages, and conducting advanced statistical analyses like Repeated Measures ANOVA.
Please share this post on social media to help fellow data enthusiasts discover the benefits of rpy2. Please comment below if you have any questions, suggestions, or requests for future tutorials.

Hi, thanks for posting this. I think you may need ‘rpackages.importr’ in place of ‘importr’ when importing the afex and lsmeans packages. That’s what worked for me anyway.
Hey Sam,
Thanks for the comment and correction,
I will have a look and will update the code later,
Erik
Thanks Sam – yes, good example Erik as I stumble through learning this, but the suggestion above by Sam is what worked.
Oh. I’ll update the post. I’ve been busy finishing up my Ph.D. thesis so this blog have not been updated that much lately.