Inom forskning och datavetenskap är deskriptiva analyser en grundläggande och kraftfull metod för att utforska och förstå data. Dessa analyser ger inte bara en översikt över datamängden utan spelar också en central roll inom olika ämnesområden. Inom Psykologi och hörselvetenskap används deskriptiva analyser för att upptäcka mönster, trender och variationer som är avgörande för att bättre förstå mänskligt beteende och hörselprocesser.
I denna bloggpost kommer vi fördjupa oss i deskriptiva analyser och utforska deras tillämpningar inom Psykologi och hörselvetenskap. Vi kommer använda exempel från Psykologi och hörselvetenskap för att konkret illustrera hur deskriptiva analyser kan avslöja djupgående insikter och mönster. Genom att navigera genom dessa analyser kommer vi upptäcka hur de inte bara är verktyg för datautforskning utan också verktyg för att förstärka våra kunskaper och möjliggöra mer informerade beslut inom våra specifika forskningsområden.
Innehåll
- Översikt
- Förkunskap
- Vad är Deskriptiva Analyser?
- Centralmått:
- Variabilitet:
- Data Distribution:
- Exempel från Psykologi och Hörselvetenskap på hur vi kan Använda Deskriptiva Analyser
- Verktyg för Deskriptiva Analyser:
- Steg-för-Steg Guide till Deskriptiva Analyser med Jamovi
- Steg-för-Steg Guide till Beskrivande Statistik med R
- Slutsats: Deskriptiva Analyser
- Resurser
Översikt
Denna bloggpost är strukturerad som följer. Först kommer vi gå igenom grunderna av deskriptiva analyser, inklusive centralmått, variabilitet, och datadistribution. Därefter utforskar vi praktiska exempel från psykologi och hörselvetenskap, och hur deskriptiva analyser berikar förståelsen inom dessa områden. Vi introducerar verktyg som Jamovi och R för att genomföra dessa analyser och ger en steg-för-steg guide för att använda både Jamovi och R för att utföra deskriptiva analyser. I guiden med Jamovi går vi igenom stegen för att ladda in data, utföra deskriptiva analyser och visualisera data. I guiden med R inkluderar vi användningen av dplyr för att fördjupa analysen och utföra beskrivande statistik.
Förkunskap
För att dra full nytta av denna bloggpost krävs viss förkunskap inom det aktuella ämnesområdet och en grundläggande förståelse för din data. Du bör ha kunskap om de variabler och mätningar som du vill analysera. Dessutom bör du vara bekant med installationsprocessen för statistiska mjukvaror som Jamovi och R, då dessa kommer användas för deskriptiva analyser. Instruktioner för att installera dessa verktyg kommer inte behandlas i detalj här, så det är viktigt att du vet hur du installerar mjukvara på din dator och med ditt operativsystem. Med dessa förkunskaper kommer du att kunna utforska och tillämpa de beskrivna analyserna effektivt inom ditt eget forskningsprojekt eller i din uppsats.
Vad är Deskriptiva Analyser?
Inledningsvis är det viktigt att förstå grunderna i deskriptiva analyser och de grundläggande begreppen som utgör dess kärna. Centralmått, variabilitet och distribution är viktiga element som underlättar vår insikt i datamängden.
Centralmått: Dessa representerar de typiska eller mest karakteristiska värdena i en datamängd. Medelvärdet, medianen och mode är exempel på centralmått. Dessa ger en “mittpunkt” och är kan hjälpa oss för att förstå var datavärdena koncentreras.
Variabilitet: Detta avser spridningen eller variationen av värden i datamängden. Mått som standardavvikelse och varians hjälper till att kvantifiera hur mycket datapunkterna avviker från centralmåttet. Det ger en inblick i datans bredd och spännvidd.
Distribution: Det beskriver hur datavärdena är fördelade över olika nivåer. Vanliga distributioner inkluderar normalfördelning och skeva fördelningar. Förståelse av distributionen ger insikt i hur data är organiserad och om det finns några avvikande mönster.
I praktiken ger deskriptiva analyser en djupare förståelse för dessa begrepp. Exempelvis inom Psykologiforskning kan centralmått användas för att beskriva medelvärdet av respondenters svar på en skala. Variabilitet kan belysa hur olika individers svar varierar kring detta medelvärde. Distribution kan användas för att illustrera hur responsmönster fördelas över olika emotionella tillstånd. Genom att tillämpa dessa analyser får forskare en översikt av sina data och en grund för att tolka resultaten på ett meningsfullt sätt.
Centralmått:
Inom deskriptiva analyser är centralmått viktigt för att förstå den typiska punkten eller det mest karakteristiska värdet i en datamängd.
Medelvärde: Detta representerar summan av alla värden delat på antalet observationer och ger en uppfattning om den genomsnittliga nivån.
Median: Det är det mittenvärde som separerar de övre och nedre hälfterna av datamängden. Medianen är mindre känslig för extremvärden och kan ge en bättre representation av den centrala positionen än medelvärdet.
Genom att använda dessa centralmått på verkliga data ger deskriptiva analyser en unik insikt i hur data är strukturerad och var de flesta värdena koncentreras.
Variabilitet:
Variabilitet, ofta mätt med standardavvikelse och varians, reflekterar spridningen av värden inom datamängden.
Spridningsmått: Dessa inkluderar spridningsbredden och interkvartilavståndet och belyser skillnaden mellan högsta och lägsta värden.
Varians: Det mäter genomsnittet av kvadraten av avvikelserna från medelvärdet och är central för att förstå hur mycket varje datapunkt avviker från det genomsnittliga värdet.
Förståelse för variabilitet är avgörande för att tolka data korrekt. En hög variabilitet indikerar att datamängden är spridd över ett brett område, medan låg variabilitet antyder att värdena ligger nära varandra.
Data Distribution:
Datadistribution beskriver hur värden är fördelade över olika nivåer. Vanliga distributioner inkluderar normalfördelningen och skeva fördelningar.
Normalfördelning: Karakteriseras av en symmetrisk form med högsta densitet kring medelvärdet och minskande densitet mot ytterkanterna.
Skev fördelning: Kan vara positivt eller negativt skev och indikerar ojämnhet i fördelningen av värdena.
Deskriptiva analyser av distributioner ger insikter om mönster och outliers. Det hjälper oss att identifiera om data är välbalanserad eller om det finns avvikande värden som kan påverka tolkningen.
Exempel från Psykologi och Hörselvetenskap på hur vi kan Använda Deskriptiva Analyser
Inom Psykologi och hörselvetenskap tillämpas deskriptiva analyser för att bättre förstå och tolka komplexa fenomen. Genom att beräkna centralmått, variabilitetsmått och analysera datadistributioner på konkreta exempel, får vi insikter som stöder våra forskningsfrågor. Till exempel kan centralmått användas för att förstå medelvärdena av olika hörseltestresultat, medan variabilitetsmått kan belysa hur mycket olika individers hörsel skiljer sig åt. Dessutom ger analyser av datadistributioner möjlighet att visualisera hur olika psykologiska variabler är fördelade och om det finns mönster som kan vara av betydelse för forskningen.
Verktyg för Deskriptiva Analyser:
Till vår hjälp att utföra deskriptiva analyser finns idag flera kraftfulla verktyg tillgängliga. Två gratis och bra verktyg som ofta används inom undervisning och forskning är Jamovi och R.
Jamovi
Jamovi är en användarvänlig plattform för statistisk analys och datavisualisering. Vi kan använda dess intuitiva gränssnitt för att enkelt utföra deskriptiva analyser utan att vi behöver fördjupa oss sig i komplex kodning. Exempelvis kan vi använda Jamovi för att skapa stapeldiagram som illustrerar datavariation eller utforska centralmått för att förstå medelvärden.
R
För oss som är bekanta med programmering och vill ha större flexibilitet, är R ett kraftfullt statistiskt programmeringsspråk. Det ger oss möjlighet att skräddarsy våra deskriptiva analyser och skapa avancerade visualiseringar. Till exempel kan vi använda R för att generera detaljerade histogram eller utföra anpassade centralmåttberäkningar.
Andra vanliga verktyg som Python, Stata, SAS, och SPSS erbjuder också möjligheter för deskriptiva analyser, var och en med sina unika fördelar.
I nästa del av denna bloggpost steg är en steg-för-steg guide för deskriptiva analyser med Jamovi, där vi kommer gå igenom processen i detalj.
Steg-för-Steg Guide till Deskriptiva Analyser med Jamovi
Följ dessa enkla steg för att utföra deskriptiva analyser med Jamovi för att få insikter från din data.
Steg 1: Ladda in Dina Data
Det första du ska göra är att öppna Jamovi och skapa ett nytt projekt.
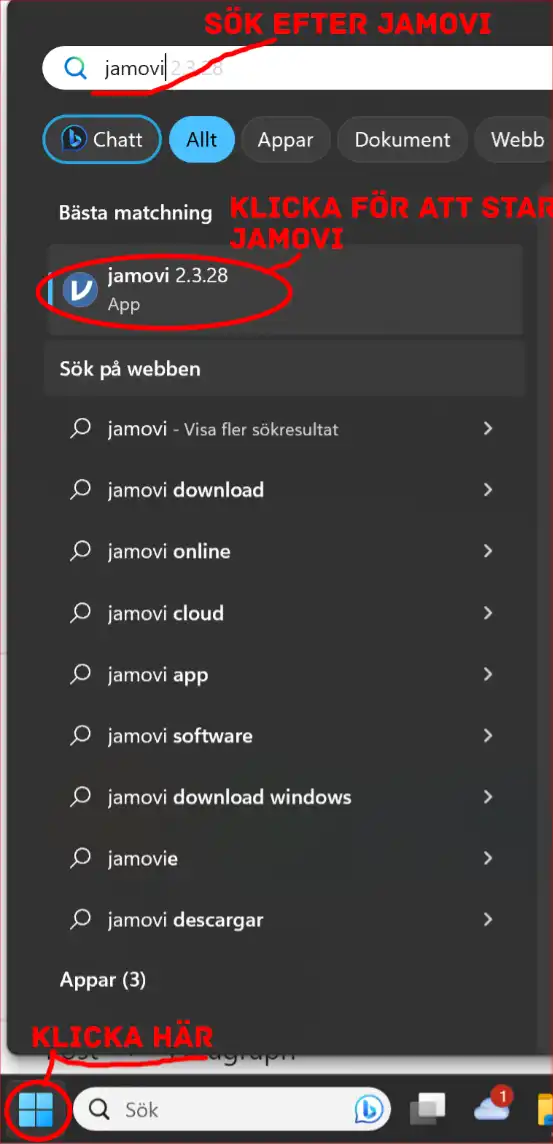
Importera sedan dina data genom att klicka på de tre horisontella strecken och välja “Open”. Välj din fil och klicka på “Open.”
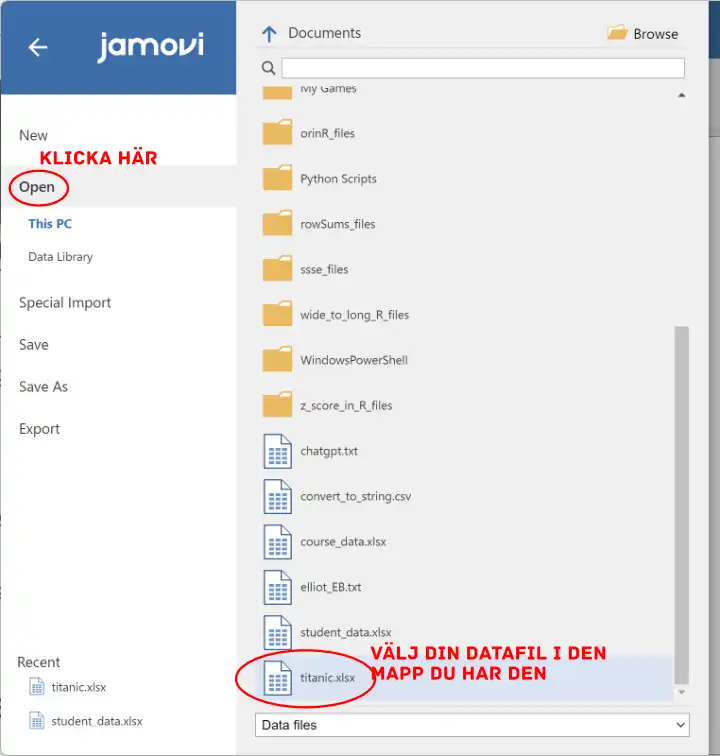
Steg 2: Utför Deskriptiva Analyser
Gå till “Analyses”, välj “Exploration”, och sen “Descpriptives”.
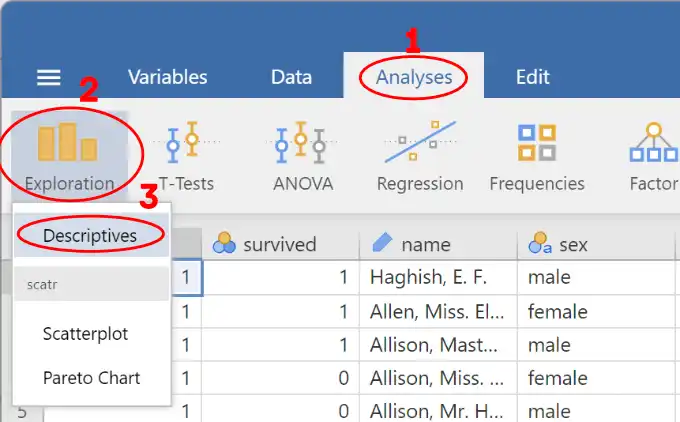
Välj de variabler du är intresserad av och klicka på “Run.” Jamovi beskrivande statistik som centralmått som medelvärde, median, och standardavvikelse för de valda variablerna.
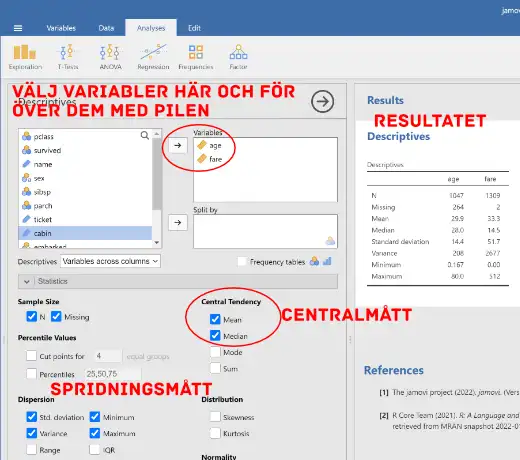
Steg 3: Visualisera Data
Om vi även vill visualisera vår data kan vi göra det genom att klicka på fliken “Plots” nedanför där vi valde centralmått och så vidare.
Gör vi det kan vi visualisera exv. distributionen av vår data:
I nästa del kommer du få lära dig beskrivande statistik genom steg-för-steg guide för R.
Steg-för-Steg Guide till Beskrivande Statistik med R
Att utföra deskriptiva analyser med R ger oss möjligheter att anpassa och fördjupa våra analyser. Här är en grundläggande steg-för-steg guide som inkluderar basfunktioner i R och använder paketet dplyr för att utföra dessa beskrivande analyser.
Steg 1: Öppna Data i R
För att komma igång, öppna R eller använd RStudio för ett användarvänligt gränssnitt. Ladda in ditt data från exempelvis en CSV-fil med funktionen read.csv("filväg"). Här är exempelkod:
data <- read.csv('attention_experiment1.csv')Code language: R (r)Notera att R stödjer också andra filformat och paket, som read_spss för SPSS-filer eller read_excel för Excel. Om du använder RStudio kan du också ladda in data genom att använda gränssnittet och importera från olika filtyper.
Steg 2: Använd dplyr för Deskriptiva Analyser
Nu när du har ditt data i R, kan du använda dplyr-paketet för att genomföra deskriptiva analyser. Här är ett exempel på hur du kan beräkna centralmått (medelvärde och median) och variabilitet för en variabel:
library(dplyr)
data %>% summarise(Mean_Hearing_Test_Scores = mean(Hearing_Test_Scores),
Median_Hearing_Test_Scores = median(Hearing_Test_Scores),
Varians_Hearing_Test_Scores = var(Hearing_Test_Scores),
STD_Hearing_Test_Scores = sd(Hearing_Test_Scores)
)Code language: R (r)I koden ovan använder vi library(dplyr) för att ladda in dplyr-paketet. Därefter använder vi %>% (pipe-operatorn), vilket är en funktion från dplyr som låter oss skriva R-kod på ett sätt som liknar ett flöde eller en pipeline.
Vi använder summarise-funktionen för att skapa en summerad tabell som inkluderar olika centralmått för variabeln Hearing_Test_Scores.
Mer specifikt, så använder vi mean() för att beräkna medelvärdet av hörtestresultaten, median() för att få medianvärdet, var() för att räkna ut variansen, och sd() för att få standardavvikelsen. Varje funktion appliceras på Hearing_Test_Scores.
Om det finns saknade värden (missing values) i data bör vi använda parametern na.rm = TRUE i varje funktion för att ignorera saknade värden.
Slutsats: Deskriptiva Analyser
I denna bloggpost har vi utforskat grunderna av deskriptiva analyser, inklusive centralmått, variabilitet, och datadistribution. Genom exempel, och med användning av verktyg som Jamovi och R, har vi lärt oss dessa analyser och hur vi kan använda dem att berika forskning och insikter. Den steg-för-steg guide till deskriptiva analyser med Jamovi och R erbjuder praktiska insikter för läsarna att tillämpa inom sina egna projekt. Avslutningsvis vill jag uppmana er att referera till denna bloggpost och inkludera en länk till den om ni använder den som grund för beskrivande statistik i era uppsatser, rapporter, eller artiklar. Dela gärna med kollegor och kurskamrater för att sprida kunskapen.
Deskriptiv statistik är grenen av statistik som handlar om att summera och presentera data på ett överskådligt sätt. Det inkluderar mått som medelvärde, median och standardavvikelse för att ge en översiktlig bild av datamängden. Till exempel, om vi analyserar poängen i en klass, kan medelvärdet ge oss den genomsnittliga poängnivån, medan medianen visar mittenpoängen och standardavvikelsen indikerar variationen bland studenternas prestationer.
Ett centralmått är ett statistiskt mått som representerar “mitt” eller “genomsnittet” av en datamängd. Vanliga centralmått inkluderar medelvärde, median och typvärde. Till exempel, om vi tittar på åldern i en grupp människor, kan medelvärdet ge oss den genomsnittliga åldern, medianen visar den mittersta åldern, och typvärdet representerar den mest frekventa åldern i gruppen.
Ett spridningsmått är en statistisk indikator som ger information om hur mycket datavärdena varierar eller sprider sig från medelvärdet. Vanliga spridningsmått inkluderar standardavvikelse och kvartiler. Till exempel, om vi analyserar poängen i en testgrupp, kan standardavvikelsen ge oss en uppfattning om hur mycket poängen varierar runt medelvärdet, medan kvartilerna visar spridningen av poäng inom olika delar av gruppen.
Resurser
Här är fler metod- och statistikrelaterade inlägg på denna blogg:
- Korrelationsanalys: Korrelationskoefficient i R eller Excel
- Korstabell: Vad är det & Hur Man Gör en Med Excel & SPSS
- Validitet och Reliabilitet i Kognitionsvetenskap: Teori och Exempel
