Exploring response time distributions using Python
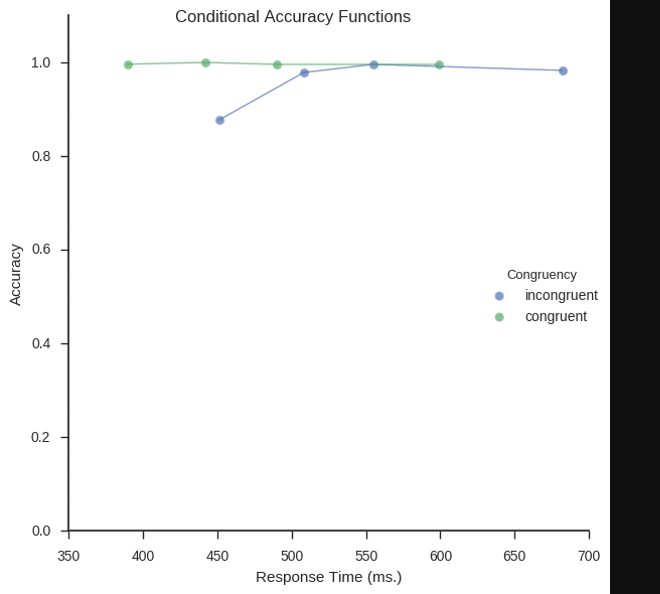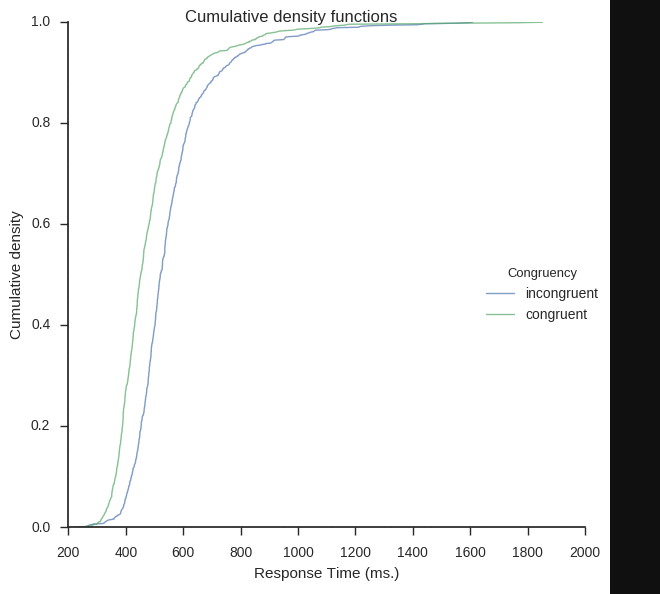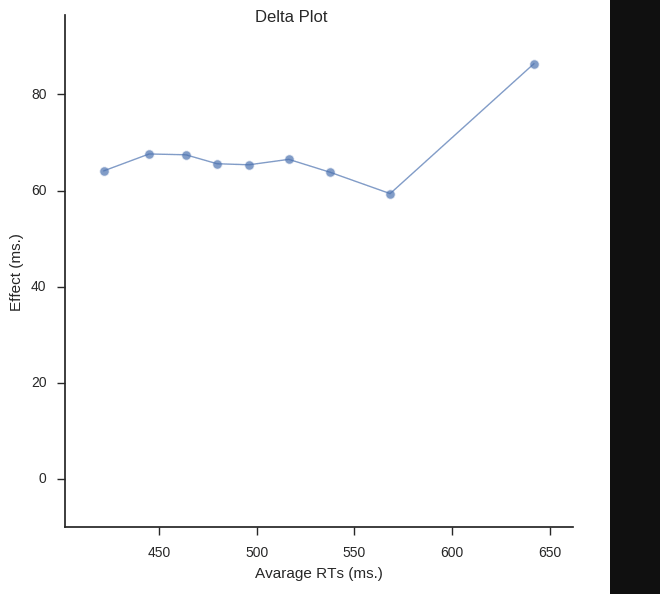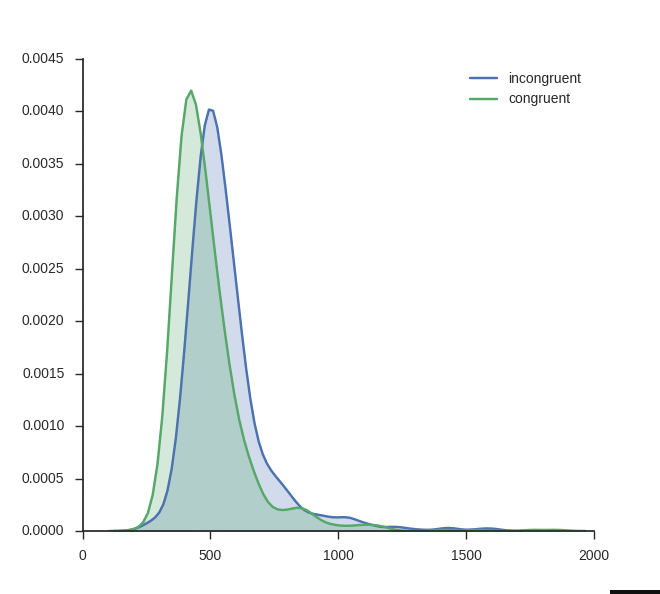
Inspired by my post for the JEPS Bulletin (Python programming in Psychology), where I try to show how Python can be used from collecting to analyzing and visualizing data, I have started to learn more data exploring techniques for Psychology experiments (e.g., response time and accuracy). Here are some methods, using Python, for visualization of […]
Exploring response time distributions using Python Read More »